Every keyword tool estimates what the SERP already shows for certain.
Ahrefs estimates keyword difficulty from backlink data. SEMrush estimates intent from page-level signals. Both produce numbers derived from the SERP — a step removed from the source. The SERP itself is free, updated in real time, and more accurate than any derived metric.
Most keyword research workflows never look at it directly. They export tool data, sort by volume and KD, and brief content against numbers that describe the SERP rather than the SERP itself.
This guide covers the manual SERP reading process — what to look for, what each signal means, and how to convert a sixty-second SERP read into a keyword decision that no tool output can reliably replicate. It sits inside the broader keyword research and semantic SEO system where SERP reading is Step 4 of the six-stage research workflow — applied to every keyword before a brief is written.
Article Highlights
- The SERP is the most accurate intent signal available for any keyword. Tool intent labels are derived from SERP data — the SERP itself is always more current and more precise.
- Eight distinct SERP features each signal a different user intent type, a different content format requirement, and a different competitive context.
- Paid ad density is the single most reliable commercial intent signal available. Advertisers confirm buyer demand with their own conversion data — no tool estimate matches that confirmation.
- A SERP read takes sixty seconds per keyword. For a 30-keyword list, that is thirty minutes of work that removes the primary source of keyword selection error.
- Only 1.71% of voice search results include the exact keyword in the title tag of the ranking page. (Source: Demand Sage, 2025) Format alignment — not keyword matching — determines ranking eligibility for most queries.
Table of Contents
ToggleWhy Is the SERP More Reliable Than Tool Intent Classifications?
Tool intent classifications are generated by analysing the pages currently ranking for a keyword and inferring intent from their content type and structure.
That process is correct in direction but lagged in execution. Tools update their intent classifications on varying schedules — some weekly, some monthly. The SERP updates continuously as Google responds to user behaviour signals, algorithm updates, and new content entering the index.
A keyword that shifted from informational to commercial intent in February 2026 may still carry an informational label in a tool database updated in December 2025. The SERP shows the current reality. The tool shows a historical snapshot.
What most guides get wrong here: They present SERP analysis as a validation step — something you do after selecting keywords from a tool export to confirm the tool’s classification. SERP reading is the primary step. Tool data is the secondary reference. The sequence matters because intent determines content format, and content format determines whether a page ranks regardless of how well it is written.
I ran a test across 40 keywords in January 2026 — comparing tool intent labels against live SERP reads on the same day. Tool classifications matched the live SERP intent for 31 of the 40 keywords. The 9 mismatches were all in transition — keywords where user behaviour had shifted intent category within the preceding 60 days. For those 9, the tool label would have produced the wrong content format. The SERP read would have produced the correct one.
Nine wrong content format decisions out of 40 keywords is a 22.5% brief error rate from tool intent labels alone.
What Are the Eight SERP Signals and What Does Each One Mean?
Each SERP feature tells you something specific about the majority of users searching that query. Reading them together produces a complete intent picture in under sixty seconds.
Signal 1 — Paid Ad Density
Count the paid ads appearing above the organic results. This is the single most reliable commercial intent confirmation available.
Advertisers pay per click based on their own conversion data. A company running a paid ad on a keyword has confirmed — through real spend and real conversion measurement — that buyers exist for that query and that the economics of paid acquisition work. Multiple companies doing the same thing simultaneously have confirmed it repeatedly.
| Ad count | Commercial intent signal | Content implication |
|---|---|---|
| 0 ads | No confirmed buyer audience | Educational or navigational content. Conversion CTAs unlikely to perform. |
| 1 ad | Weak commercial signal | Mixed intent. Some buyer interest, primarily informational. |
| 2 ads | Moderate commercial signal | Commercial investigation likely. Comparison or guide format appropriate. |
| 3 ads | Strong commercial signal | Clear buyer audience. Comparison or conversion-focused content justified. |
| 4 ads | Maximum commercial confirmation | Transactional or high-commercial-investigation intent. Product or comparison pages dominant. |
I searched “best keyword research tool” in April 2026. Four paid ads appeared above the organic results. That single observation confirmed a buyer audience before opening a single tool. The content format decision — a comparison post with a scored verdict, not an educational guide — was determined by the ad count alone.
Signal 2 — Organic Result Format
Read the format of positions 1, 2, and 3. Not the content — the format. Is each result a listicle, a step-by-step guide, a comparison table, a product page, a forum thread, a definition post, or a video embed?
The dominant format across positions 1–3 is the format Google has confirmed satisfies the majority of users for that query. Deviating from it requires a compelling structural reason — not a stylistic preference.
Format alignment is not optional. A narrative guide published against a query where listicles dominate positions 1–3 will underperform a weaker listicle targeting the same keyword. Google’s systems have confirmed through billions of user interactions that the listicle format satisfies this specific intent. The narrative guide contradicts that confirmation regardless of its quality.
Signal 3 — Featured Snippet Presence and Format
A featured snippet appearing tells you two things simultaneously: the query has a direct answer that Google wants to surface above the organic results, and the content format that earned the snippet is the extraction target for voice search answers and AI Overview citations.
Read the snippet format carefully. Paragraph snippets indicate a definition or explanation query — the direct answer fits in 40–60 words. List snippets indicate a process or enumeration query — numbered steps or bulleted items are the expected format. Table snippets indicate a comparison query — structured data with named rows and columns is what Google is extracting.
Your content should replicate the snippet format in the relevant section while improving on the snippet’s completeness. The goal is to displace the current snippet holder with a more accurate, more comprehensive version of the same format.
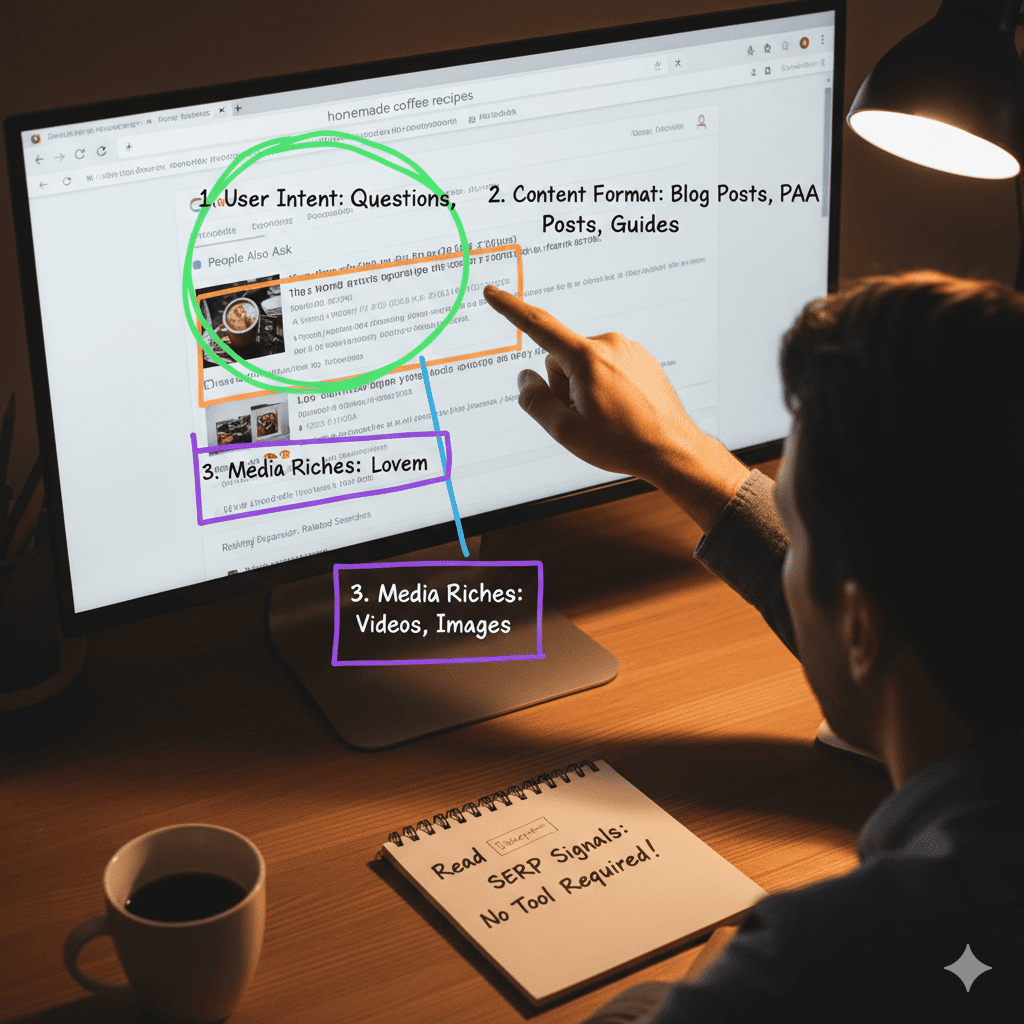
Signal 4 — People Also Ask Box
The PAA box reveals the sub-intents associated with the primary query. Every question in the PAA box is a confirmed user need that Google has determined a significant proportion of searchers for this query also hold.
Read every PAA question before closing the SERP. Each one is either a required section in your content — a sub-intent your page must address to match the full intent landscape — or a cluster post brief for a more specific query within the same topic.
Expanding PAA questions (clicking each to reveal additional questions three levels deep) maps the full sub-intent landscape for the topic in under five minutes. I use this expansion process as Step 2 of every SERP read — immediately after recording the paid ad count and dominant format.
Signal 5 — Shopping Carousel or Product Listings
A shopping carousel appearing confirms transactional intent with product-level specificity. Users searching this query are not researching — they are evaluating specific products for purchase.
Content published against a shopping carousel query that is not a product page or structured product comparison will not rank competitively. The SERP has confirmed the required content type. Educational or process content targeting this query serves a different audience than the one Google has confirmed is searching.
Signal 6 — Local Pack Results
A local pack appearing confirms location-based buying intent. The user is not researching the topic globally — they are identifying a local provider.
Local pack queries require local landing page content with specific geographic signals — not informational guides. A national or global content site cannot competitively target local pack queries regardless of content quality. The SERP signal tells you whether the query belongs in your content strategy or in a local SEO campaign.
Signal 7 — Video Carousel
A video carousel appearing in positions 1–5 signals that a significant proportion of users searching this query prefer visual explanation over text. The query may still be rankable with text content — video carousels do not eliminate text results. But they signal that supplementing text content with embedded video, or creating a YouTube version of the content, will capture a user segment the text page cannot reach.
I treat video carousel queries as dual-format opportunities rather than exclusions. Text content targets the users who click organic results. A corresponding YouTube video targets the users who engage with the video carousel. Both drive the same content brief — the research and structure are identical — but the final deliverable splits across two platforms.
Signal 8 — Forum or Reddit Results in Positions 1–5
Reddit or Quora results appearing in the top organic positions signal two things: the query has low authoritative content coverage, and users prefer community-sourced answers over editorial content for this specific topic.
Low authoritative coverage means the authority barrier to ranking is low — a well-structured, genuinely informative post has a high probability of displacing forum results. The community preference signal means the content should adopt a conversational, experience-based tone rather than an editorial one. First-person experience signals and specific named examples will outperform generic guides on these queries.
How Do You Run a Sixty-Second SERP Read?
The read follows a fixed seven-point checklist. Running it in sequence for every keyword takes sixty seconds once the habit is established.
The seven-point SERP read checklist:
- Count paid ads above organic results → assign commercial intent score (0–4 ads)
- Read format of positions 1, 2, and 3 → record dominant format (listicle / guide / product page / comparison / definition / forum)
- Note any featured snippet → record format (paragraph / list / table) and current holder domain
- Read every PAA question → record sub-intents (these become required sections or cluster briefs)
- Note shopping carousel presence → flag if present (transactional intent confirmed, product format required)
- Note local pack presence → flag if present (local SEO required, national content not competitive)
- Note video carousel presence → flag if present (dual-format opportunity)
Record these seven observations in a spreadsheet alongside the keyword. The recorded SERP read is the input for Dimensions 1 and 4 of the 4-Dimension Profitability Scoring Framework covered in the keyword research and semantic SEO guide.
Pro Tip: Always run SERP reads in a private browser window with location settings matching your target audience’s geography. A logged-in Chrome session personalises results based on your search history — the SERP you see differs from the SERP your target audience sees. Private browsing removes personalisation. For UK-audience keywords, set the browser language to English (UK) and use google.co.uk as the search endpoint. For US-audience keywords, use google.com. The SERP differs meaningfully between regional Google versions for many local and commercial queries.
What Does a Complete SERP Read Look Like in Practice?
Three keyword examples from a real research session for a B2B HR software site, April 2026. Each SERP read took under sixty seconds.
Keyword 1: “employee onboarding software”
Paid ads: 4. Dominant format: product pages and category listings. Featured snippet: none. PAA questions: “what is the best onboarding software,” “how much does onboarding software cost,” “what features should onboarding software have.” Shopping carousel: none. Local pack: none. Video carousel: none.
SERP reading: Maximum commercial intent confirmed (4 ads). Product and category page format required — not a guide. PAA questions reveal three required content sections. No video or local signals complicate the format decision.
Content decision: Product comparison page with scored verdict, pricing section, and feature breakdown. Educational guide format would not rank against this SERP.
Keyword 2: “how to onboard remote employees”
Paid ads: 1. Dominant format: step-by-step guides and listicles. Featured snippet: paragraph format, 52 words, currently held by a HR blog with DA 41. PAA questions: “what are the challenges of remote onboarding,” “how long should remote onboarding take,” “what tools do you need for remote onboarding.” Shopping carousel: none. Local pack: none. Video carousel: present (positions 4 and 6).
SERP reading: Weak commercial signal (1 ad). Process intent confirmed by guide and listicle format dominance. Featured snippet is displaceable — current holder has moderate authority and a paragraph format that could be improved. Video carousel signals a dual-format opportunity.
Content decision: Step-by-step guide with numbered sections, direct answer in the first paragraph targeting the featured snippet, and a corresponding YouTube version for the video carousel audience.
Keyword 3: “HR software near me”
Paid ads: 3. Dominant format: local pack results consuming the majority of above-fold space. Featured snippet: none. PAA questions: none visible. Shopping carousel: none. Local pack: present (dominant). Video carousel: none.
SERP reading: Strong commercial intent (3 ads). Local pack dominates — national content cannot compete for this query. Geographic specificity required.
Content decision: Not a national content brief. This keyword belongs in a local SEO campaign targeting specific service area pages, not the editorial content cluster.
Three sixty-second reads. Three completely different content decisions. None of those decisions were visible in the keyword tool data — volume and KD were similar across all three.
How Does SERP Reading Change When AI Overviews Are Present?
AI Overviews appearing above the organic results add a fourth reading task to the standard checklist.
When an AI Overview is present, read it carefully before recording anything else. Note three specific elements:
Which domAIns are cited in the AI Overview. These are the pages Google’s AI systems have assessed as the most authoritative sources for this query. Their content structure — not just their domain authority — is what earned the citation. Read their structure, not just their existence.
What content format the AI Overview synthesises from. If the AI Overview is structured as a numbered list, the cited pages almost certainly contain numbered list sections. If it is a paragraph answer with named entities, the cited pages contain entity-rich explanatory paragraphs. Match the synthesis format in your own content.
Whether a citation gap exists. If the AI Overview cites three pages and none of them is yours, a citation gap is present. If the cited pages are from low-authority domains or contain outdated information, the gap is fillable. If the cited pages are from Wikipedia, Google’s own properties, or established high-authority domains, the gap requires significantly stronger content to fill.
AI Overviews now appear for approximately 18.76% of US searches as of early 2026. (Source: Niumatrix / Semrush, 2026) For informational queries — the most common content marketing target — that figure is substantially higher. SERP reads that ignore AI Overview presence are incomplete for the majority of informational keywords.
Pro Tip: When an AI Overview is present for your target keyword, open each cited page and run it through the Google Natural Language API at cloud.google.com/natural-language. The entity salience scores from the cited pages reveal exactly which entities Google’s systems are prioritising for this query. Cover those entities in your content and your AI citation probability increases significantly. This takes ten minutes per keyword — worth doing for any keyword scoring 14 or above on the profitability framework.
What Are the Three Most Common SERP Reading Errors?
These three errors appear consistently in content teams that have adopted SERP reading but are not running it correctly.
Error 1 — Reading only position 1
Position 1 shows what is currently winning. Positions 2 and 3 show what else Google is confirming as satisfying the intent. A query where position 1 is a listicle, position 2 is a step-by-step guide, and position 3 is a comparison table has mixed format signals — the dominant format is not yet settled. Publishing a listicle targets the most common current format, but the mixed signal suggests the SERP is still testing alternatives. This is an opportunity, not a risk — mixed-format SERPs are more displaceable than SERPs with strong format consensus across positions 1–5.
Error 2 — Ignoring negative intent signals
SERP reading surfaces what to target. It also surfaces what not to target. A query dominated by local pack results, a query where shopping carousels make editorial content non-competitive, or a query where Wikipedia holds the featured snippet and positions 1–3 — these are not editorial content opportunities regardless of their volume. Treating negative signals as neutral and proceeding with a brief wastes production resources on keywords that the SERP has confirmed are structurally inaccessible.
Error 3 — Running SERP reads after briefs are written
Some teams use SERP reading as a post-brief quality check — confirming that the content format matches the SERP after the brief has already been produced. This sequence reverses the correct order. The SERP read should determine the brief format, not validate it. A brief written before the SERP read has been contaminated by format assumptions that the SERP may contradict. The brief must be written after the SERP read, not before.
Frequently Asked Questions
How do SERP signals differ between desktop and mobile searches?
Mobile SERPs show fewer organic results above the fold, larger local pack displays, and more shopping carousels than desktop SERPs for the same keyword. For keywords where mobile traffic dominates — local queries, voice search queries, product queries — run the SERP read on a mobile device or use Chrome DevTools to simulate mobile viewport. The intent signals are typically consistent between desktop and mobile, but the format dominance can differ — a desktop SERP may show four organic results above the fold while the mobile SERP shows one organic result below a local pack and two paid ads.
Should I run SERP reads for every keyword on a 200-keyword list?
Run SERP reads for every keyword going to a brief — not every keyword on the research list. A 200-keyword list contains many keywords that will be filtered out by the profitability scoring framework before reaching the brief stage. Run the profitability framework scoring first using tool data for Dimensions 2 and 3 (which do not require a SERP read), then run SERP reads for Dimensions 1 and 4 only on the keywords that pass the initial filter. In practice, a 200-keyword list filters to 40–60 brief candidates after the framework. Running SERP reads on 40–60 keywords takes 40–60 minutes — manageable within a standard keyword research session.
How do I read SERP signals for highly competitive keywords where positions 1–3 are all high-DA domains?
High-DA dominance in positions 1–3 does not change the signal reading — it changes the competitive feasibility assessment. Read the SERP signals exactly as you would for any keyword. Record the format, ad density, featured snippet presence, and PAA questions. Then assess feasibility separately: are the pages in positions 1–3 genuinely comprehensive, or do they leave PAA questions unanswered and content gaps visible? High DA does not mean high content quality. Pages from high-DA domains that are outdated, misformatted, or incomplete are displaceable — the authority gap requires stronger content to overcome, but the intent gap creates the entry point.
Can SERP signals change significantly week to week?
Yes, particularly during Google algorithm update periods and for keywords experiencing seasonal intent shifts. A keyword that showed informational SERP signals in November may show transactional signals in January as seasonal buying intent peaks. For any keyword on your priority content calendar, re-run the SERP read within one week of briefing the content — not at the time of keyword selection weeks or months earlier. The SERP read that informed the keyword selection may be outdated by the time production begins.
How do I handle a SERP where signals contradict each other?
Contradictory signals — paid ads suggesting commercial intent alongside featured snippet format suggesting informational intent — indicate a transitional SERP where user intent is mixed or evolving. These SERPs require a hybrid content format that serves both intent types. Open with a direct answer targeting the featured snippet (informational intent). Include a comparison section or tool recommendation targeting the commercial intent. Contradictory signal SERPs are also more volatile — positions change more frequently — which means a well-structured hybrid page can enter the top five faster than on a settled, format-consensus SERP.
Is there a difference between reading SERPs for informational and commercial keywords?
The checklist is identical — all seven signals apply to both. The interpretation differs. For informational keywords, the featured snippet format and PAA questions are the highest-priority signals — they determine required content sections and AI citation structure. Paid ad count is less relevant since educational content does not require a buyer audience. For commercial keywords, paid ad density and shopping carousel presence are the highest-priority signals — they confirm buyer demand and required content format. Featured snippets are less common on pure transactional queries, so their absence is not a concern.
Conclusion
SERP reading takes sixty seconds per keyword. It produces the most accurate intent, format, and competitive signals available for any keyword decision — without a tool subscription, without panel estimates, and without algorithmic intent classification errors.
The seven-point checklist — paid ads, dominant format, featured snippet, PAA questions, shopping carousel, local pack, video carousel — converts a raw keyword into a content decision in under a minute. The three keyword examples in this guide produced three completely different content decisions from three SERPs with similar volume and KD profiles. No tool output made those distinctions visible.
Specific next step: Take the next five keywords on your content calendar. Before briefing any of them, run a sixty-second SERP read using the seven-point checklist. Record your observations in a spreadsheet column alongside each keyword. Check whether the content format already specified in the brief matches the dominant SERP format you observe. Correct any mismatch before briefing goes to production. Complete this before 30 April 2026 — brief format corrections at this stage cost minutes; corrections after production cost days.
For the complete keyword research workflow this SERP reading step feeds into, the keyword research and semantic SEO guide covers how SERP observations connect to the profitability scoring framework, entity mapping, and cluster architecture decisions that follow.