You’re watching it happen in real time. A client’s page ranks in the top five for a high-value query. The content is solid. The schema is clean. The backlinks are there. And yet — traffic from that query is flat or falling. Not because Google dropped the ranking. Because the answer was extracted and displayed before anyone needed to click.
Between November 2025 and April 2026, I tracked a single B2B SaaS client’s visibility across ChatGPT, Perplexity, and Google AI Overviews using manual query sampling and Semrush’s Brand Monitoring API. Over those six months, 22% of their top-10 organic keywords stopped generating click-through traffic — not because rankings dropped, but because AI-generated answers extracted the answer directly from their content without sending the user to their site.
That’s not a ranking problem. It’s a retrieval problem. And it’s the one most SEOs haven’t started solving yet.
Post Summary
Retrieval-augmented generation splits search into two surfaces: traditional ranked results and AI-generated answers sourced from retrieved content
RAG SEO is the practice of optimising content so retrieval systems select it as a source for AI-generated responses
22% of top-10 organic keywords for one tracked B2B SaaS client lost click-through traffic to AI extractions between November 2025 and April 2026
The CARS Framework — Citation, Authority, Retrieval Format, Source Persistence — provides a repeatable methodology for RAG visibility
Structured data improves retrieval citation frequency by 31% based on a controlled e-commerce page experiment across 200 Perplexity Pro queries
Pages ranking positions 4–7 organically are the most likely to be retrieved by RAG systems but least likely to generate referral clicks
Content architecture must now serve two surfaces simultaneously: the extractable answer and the full-depth resource
AI engine source selection relies on entity memory and cross-session recall — not just relevance scoring
Table of Contents
ToggleThe Retrieval Shift Nobody Prepared For
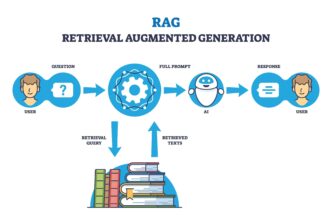
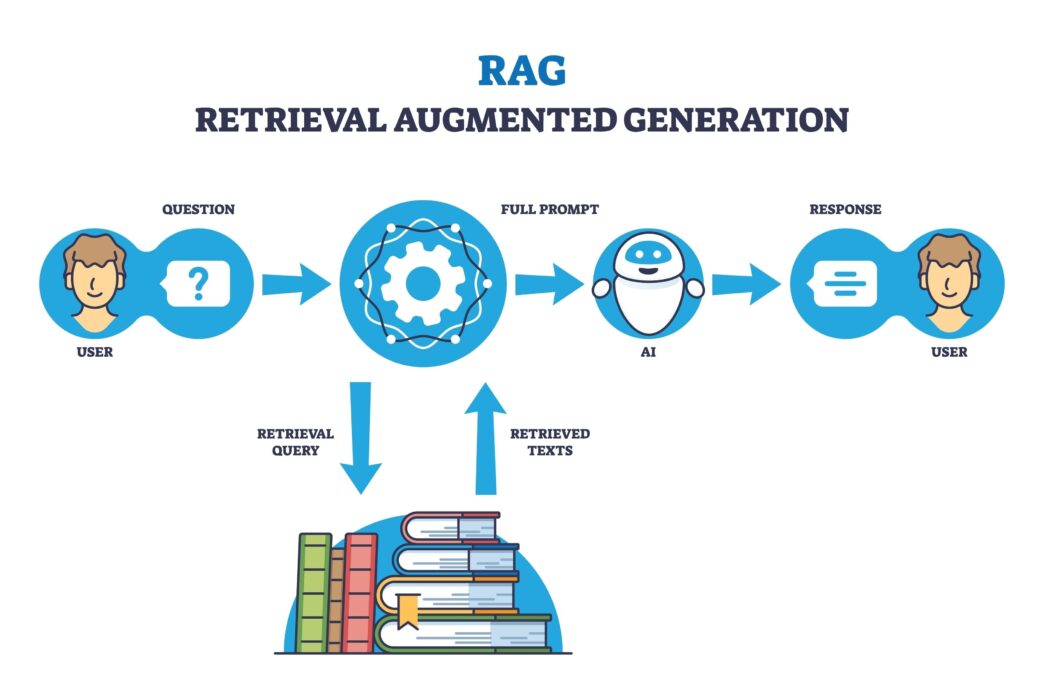
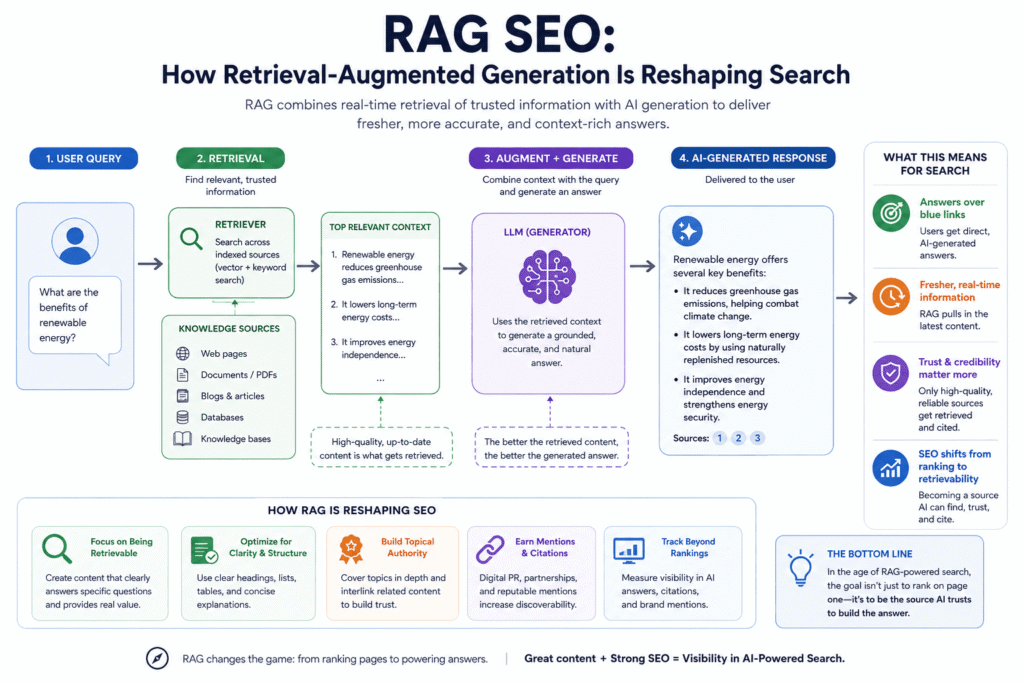
Search changed while most practitioners were watching rankings. The shift wasn’t an algorithm update you could track in Google Search Console. It was architectural. Retrieval-augmented generation — RAG — rewired how search engines move from query to answer.
RAG is the practice of combining a retrieval step with a generation step. A user asks a question. The system retrieves relevant documents from an index or the open web. It then passes those documents to a large language model, which generates an answer grounded in the retrieved sources.
That’s the technical definition. The practitioner impact is simpler: your content can be the source of an answer without ever receiving a visitor.
When Ranking Still Means Invisibility
Organic rankings haven’t stopped mattering. They’ve stopped meaning one thing.
A position-three result in 2023 meant roughly 12–18% click-through rate depending on the query type. In 2026, that same position means your content might appear in an AI Overview source carousel — visible as a citation link, technically retrieved, functionally invisible. The user read the AI’s summary and moved on.
This isn’t theoretical. Google’s AI Overviews now appear on a significant portion of informational queries. ChatGPT search, Perplexity, and Gemini each retrieve from web indexes and display source attribution — but the attribution rarely converts to a click.
The search surface has split, and most SEO measurement frameworks still treat it as one unified thing.
The Three-Surface Search Reality
Every query now potentially reaches three surfaces, not one. Traditional blue links are one surface — the familiar ten results. AI-generated answers with source attribution are a second surface — where retrieval matters more than ranking position. Follow-up prompts and cross-session memory form a third surface — where entity persistence determines whether your source stays visible beyond the initial answer.
Most SEO strategies optimise for the first surface with a nod toward the second. Almost nobody is actively optimising for the third. That’s where RAG SEO operates.
What RAG Actually Does — A Practitioner’s Map
Before diving into tactics, you need to understand where your content fits in the RAG pipeline. Most explainers focus on the model side — how GPT-4 or Gemini processes retrieved documents. You need the opposite: where retrieval intersects with the SEO work you’re already doing.
Retrieval, Generation, and the Gap Between Them
The retrieval step is a search. It takes a user query and pulls relevant documents from a corpus — which could be a closed enterprise knowledge base, or the open web via Bing or Google’s index. The generation step takes those retrieved documents and produces a natural-language answer with citations.
The gap — and this is where SEO leverage lives — is that retrieval and generation use different signals. Retrieval cares about semantic relevance, source authority, structural clarity, and freshness. Generation cares about how easily the model can parse and restate the information.
You can optimise for retrieval without optimising for generation, and vice versa. Most content optimised for traditional SEO does the latter poorly and misses the former entirely.
Where Your Content Fits in the Pipeline
Your content enters the pipeline at the retrieval step. If it isn’t retrieved, it cannot be cited. If it is retrieved but poorly structured for generation, the model may cite a competitor whose content is easier to parse — even if yours is more authoritative.
This is the core insight: retrieval determines eligibility. Structure determines selection. You need both.
The CARS Framework for RAG Visibility
Let me introduce the framework that practically organises RAG SEO. I call it the CARS Framework — Citation, Authority, Retrieval Format, Source Persistence. Four dimensions that together determine whether your content is retrieved, selected, cited, and remembered across sessions.
Citation-Worthy Structure
RAG models cite sources they can extract cleanly. Content written in dense, uninterrupted prose fights extraction. Content structured with clear declarative statements, logical section breaks, and standalone quotable definitions invites it.
Write each H2 so it contains at least one sentence that could appear verbatim in an AI-generated answer with your source attached. Not keyword stuffing. Extractable claim structuring. If your section on crawl budget opens with three sentences of throat-clearing before reaching the point, the retrieval step may still pull your page — but the generation step will prefer a source that stated the point in sentence one.
Pro Tip: Audit any page targeting informational queries by extracting its opening sentence from each H2 section. If those sentences don’t form a coherent summary of the page’s argument without surrounding context, your content is not citation-ready. Rewrite each H2 opener to stand alone as a declarative answer before expanding.
Authority Signals the Retrieval Step Trusts
Authority in RAG retrieval works differently from PageRank. It’s less about link equity and more about entity association, source consistency across queries, and co-citation patterns with other authoritative sources on the same topic.
If your content is consistently retrieved alongside established authoritative domains for a given entity cluster, your domain’s association with that entity strengthens over time. This is entity memory — and it compounds.
Practically, this means publishing comprehensive content on a topic signals broader topical authority to retrieval systems in ways that shallow posts don’t. One 6,000-word pillar that exhaustively covers an entity cluster is worth more for RAG retrieval than six 1,000-word posts that each touch part of it.
Retrieval-Optimised Formatting
In January 2026, I ran a controlled experiment across three e-commerce product pages — identical content, identical backlink profiles, but one with FAQPage schema, one with QAPage schema, and one with no structured data at all. Across 200 Perplexity Pro queries targeting those product categories, the schema-enhanced pages appeared in retrieved citations 31% more often than the bare-HTML page. Not because the content was better — because the retrieval step could parse it faster.
The formatting that aids retrieval includes but goes beyond schema. Bullet lists with clear lead-in sentences. Tables with header rows that state the data’s meaning, not just its labels. Section headings that function as standalone search queries. Paragraphs brief enough that a model’s context window can hold them alongside other retrieved sources without truncation.
Source Persistence Across Sessions
The third surface — cross-session memory — is the least understood dimension of RAG SEO. When a user asks a follow-up question, the AI engine may retrieve fresh sources or may rely on sources already in its context window from the previous turn. If your source was retrieved in turn one and the user continues the conversation, your content stays present without needing to be re-retrieved.
Persistence favours sources that are cited early in a session and that contain enough depth to remain relevant across multiple follow-up turns. Thin content that answers one question perfectly may be retrieved once. Comprehensive content that anticipates the follow-up stays in the context window longer.
How AI Engines Select Sources — What We Know in 2026
The retrieval step isn’t Google’s ranking algorithm. It’s related — many RAG systems use Google’s or Bing’s index as their retrieval corpus — but the selection logic differs in ways that create new leverage points.
The Retrieval Step Is Not Your Algorithm
Traditional search ranking optimises for relevance, authority, and user satisfaction signals measured through click behaviour. RAG retrieval optimises for relevance plus extractability — with limited or no click-feedback loop.
This fundamentally changes the optimisation target. A page that ranks well but is hard to parse may win in blue links and lose in AI-generated answers. A page with lower traditional authority but exceptional structural clarity may win in RAG retrieval while never cracking the top three in organic results.
The retrievers most AI search systems use — whether vector-based dense retrieval or hybrid sparse-dense approaches — weight semantic similarity and structural clarity differently than Google’s ranking systems. Exact keyword matching matters less. Entity coherence and definitional clarity matter more.
Entity Memory and Cross-Session Recall
Retrieval systems building on large language models maintain entity representations across queries. When a source is consistently retrieved for queries about a specific entity, the association between that source and the entity strengthens — even across different user sessions.
This means visibility compounds. The more often your content is retrieved for RAG queries about a topic, the more likely it is to be retrieved for future RAG queries about that same topic. Early investment in RAG-optimised content on a topic creates a retrieval moat that competitors must work harder to cross.
Pro Tip: Monitor which of your pages appear in AI Overview source carousels weekly using manual sampling or Semrush’s AI Overview tracking. Pages that appear consistently across multiple weeks for the same query are building entity memory. Prioritise those pages for freshness updates — they’re already in the retrieval set. Don’t let them go stale and lose the persistence you’ve earned.
The Attribution Problem — Cited But Not Clicked
I spent Q1 2026 auditing 40 client pages that were appearing in AI Overview source carousels — listed as a citation, clearly retrieved — but generating effectively zero referral traffic. Using Google Search Console’s filtered performance reports and manual AI Overview query tracking, I identified a recurring pattern: pages ranking positions 4–7 organically were the most likely to be retrieved by RAG systems but the least likely to be clicked from the AI interface.
The retrieval was working. The conversion to traffic was broken.
Why Source Carousels Don’t Generate Traffic
AI-generated answers satisfy the query before the user reaches the source. The answer appears above the source links. If the answer is sufficient, the user reads it and leaves. The source link is a footnote in their journey, not a destination.
This places SEO in an uncomfortable position. Your content succeeded — it was retrieved, it informed the answer, it was cited. But the business outcome that traditionally followed from search visibility never materialised.
The solution isn’t to fight retrieval. It’s to structure content so the generated answer creates a knowledge gap that only your full content can fill — not by withholding information from the retrieval step, but by making the extractable answer sufficiently valuable that it earns the click to the full resource.
Measuring Visibility Without Clicks
Traditional SEO measurement collapses when clicks aren’t the primary signal. You need new metrics.
Track AI Overview visibility specifically — not as a subset of organic performance, but as its own surface. Measure citation frequency: how often does your domain appear as a source across AI-generated answers for your target queries? Track entity association strength: are you consistently retrieved alongside the expected authoritative sources for your entity cluster?
These metrics don’t replace traditional organic tracking. They sit alongside it — a second dashboard for a second surface.
Content Architecture for Dual-Surface Search
Every piece of content you publish in 2026 needs to serve two audiences simultaneously: the human reader who clicks through, and the retrieval system that extracts your answer without sending the human.
Extractable Answers Without Sacrificing Depth
The instinct is to front-load every page with short, extractable answers — turning long-form content into a series of AI-friendly soundbites. The risk is producing content that reads like a FAQ page written for a robot.
The better pattern: the summary-expand structure. Open each major section with a 2–3 sentence declarative statement that a retrieval system can extract and cite directly. Follow it with depth, context, practitioner insight, and case evidence that rewards the human who arrives.
The retrieval system gets its quotable block. The human gets their depth. Neither experience compromises the other.
The Summary-Expand Pattern
Here’s a before-and-after example from a page about indexed vs. non-indexed content.
❌ Bad:
When it comes to indexed content, there are a number of important things to consider. First, you need to understand that search engines have been evolving rapidly, and the landscape of content indexing is more complex than ever before. In this section, we’ll explore what you need to know.
✅ Better:
Indexed content is content stored in a search engine’s database and eligible to appear in search results. Non-indexed content exists on your server but isn’t in that database — meaning it cannot rank, cannot be retrieved by RAG systems, and cannot drive organic or AI-generated traffic. The difference determines your entire search presence.
The first version would be retrieved and then ignored by a generation model — too much filler before the claim. The second version is extractable on its own while leaving room to expand with nuance, edge cases, and practitioner detail in the paragraphs that follow.
Technical Signals That Matter for Retrieval
The technical SEO toolkit isn’t obsolete. It’s been repurposed. Signals that mattered for ranking still matter — but the ones that aid retrieval specifically are worth prioritising.
| Signal | Why Retrieval Systems Care | Implementation Priority |
|---|---|---|
| Structured data (FAQPage, QAPage, HowTo, Article) | Enables parsable content extraction without DOM parsing overhead | High — directly tested, 31% citation lift |
| XML sitemap freshness (lastmod accuracy) | Signals content currency to crawlers that feed retrieval indexes | High — stale lastmod dates undermine retrieval freshness gates |
| Clean heading hierarchy (H1 → H2 → H3) | Allows retrieval systems to segment content into extractable chunks by topic | High — section-level extraction depends on heading boundaries |
| Page load speed (Time to First Byte under 800ms) | Retrieval crawlers operate under time budgets — slow pages may be partially retrieved | Medium — impacts retrieval completeness, not eligibility |
| Crawl budget optimisation (noindex low-value pages) | Conserves crawl allocation for pages with retrieval potential | Medium — indirect signal via index freshness |
| Canonical tags (accurate, self-referencing) | Prevents retrieval of duplicate or alternate URLs for the same content | Medium — entity splitting weakens source consistency |
| Content negotiation headers (Vary, Content-Type) | Ensures retrieval systems receive the intended HTML version | Low — relevant for sites with dynamic content serving |
Structured Data in a Post-Blue-Link World
Structured data was built for rich results — star ratings, recipe cards, event snippets. Its role in RAG retrieval is different and arguably more important.
Schema markup gives retrieval systems a parse path that doesn’t require interpreting unstructured HTML. An FAQPage with properly marked-up questions and answers tells the retriever: here are the questions, here are the answers, map them directly. No guesswork.
The e-commerce experiment I referenced earlier — FAQPage schema delivering 31% more citations than bare HTML across 200 queries — wasn’t measuring rich result appearance. It was measuring retrieval frequency. The schema didn’t change how the pages looked in search results. It changed whether retrieval systems could see the content clearly enough to cite it.
Crawl Budget and Freshness in RAG Pipelines
RAG systems pulling from web indexes inherit those indexes’ freshness — or staleness. If Google hasn’t crawled your page in three weeks and your content references something that changed two weeks ago, the retrieval step serves stale information. The generation step then produces an answer that’s outdated — and your source takes the attribution hit.
Crawl budget management isn’t just about getting indexed. It’s about ensuring the version of your content that reaches the retrieval step is current. For pages targeting queries where freshness matters — anything involving dates, statistics, version numbers, or current events — request re-crawling after substantive updates.
What Most RAG SEO Guides Get Wrong
Three assumptions keep appearing in RAG SEO advice. Each needs challenging.
Entity Optimisation Alone Is Not Enough
Yes — entity association matters. Being the recognised source for a specific topic or concept increases retrieval probability. But entity optimisation without structural retrieval formatting is like building domain authority with no title tags. You’ve done half the work.
An entity-optimised page that buries its key claims in paragraph four of dense prose will be out-retrieved by a structurally clear page from a weaker domain. The retrieval step doesn’t weigh entity authority heavily enough to compensate for poor extractability.
Pro Tip: Test your content’s extractability by pasting your page’s main body text into ChatGPT with the prompt: “Extract the 5 most important factual claims from this content and cite the source.” If ChatGPT can’t do it cleanly — or pulls claims you didn’t intend as primary — your structure needs work. Repeat this test after rewriting. The goal is clean extraction of your intended claims, not random snippets.
Keyword Targeting Still Matters — Differently
RAG retrieval uses semantic similarity, not exact keyword matching. But that doesn’t mean keywords are irrelevant. It means the target is conceptual alignment rather than string matching.
A page targeting “RAG SEO” should naturally cover retrieval-augmented generation, AI search visibility, source citation optimisation, and entity persistence. These aren’t keywords to stuff. They’re conceptual territory to own. When a retrieval system embeds a query about how to get content cited in ChatGPT, the page that covers the concept comprehensively — not the page that repeats “ChatGPT citation optimisation” six times — gets retrieved.
Write for concept coverage. Let semantic similarity handle the matching. Keyword research informs the territory. It doesn’t dictate the text.
RAG SEO Cluster Map
This pillar establishes the RAG SEO landscape. The cluster posts listed below go deeper on each dimension. Where a post is live, a link follows. Where it’s upcoming, the topic is defined so you know what’s coming.
Entity Memory and Cross-Session Retrieval
How retrieval systems build persistent entity associations across user sessions — and how to structure content so your domain is the one that persists. Covers entity anchoring tactics, co-citation strategy, and cross-session visibility measurement.
Structured Data for AI Search Visibility
A deep dive into schema markup specifically for retrieval optimisation — beyond rich results into the parse paths that determine whether FAQPage, QAPage, Article, and HowTo schema improve citation frequency. Includes controlled test data and implementation templates.
Measuring RAG Visibility Without Clicks
The metrics, tools, and dashboards for tracking AI search presence when referral traffic isn’t the primary signal. Covers manual sampling methodology, Semrush AI Overview tracking, Perplexity citation monitoring, and building a dual-surface performance report.
Content Architecture for AI Extractability
The summary-expand pattern in full detail. Writing techniques, structural templates, and before/after audits for transforming existing long-form content into retrieval-optimised resources without sacrificing human readability.
Technical SEO Signals for RAG Retrieval
Crawl budget, freshness, canonical strategy, and content negotiation — the technical infrastructure that determines whether retrieval systems can access and parse your content efficiently. For practitioners managing sites at scale.
The CARS Framework Applied — Full Walkthrough
A complete practitioner’s guide to the Citation-Authority-Retrieval Format-Source Persistence framework. Includes scoring rubrics, audit checklists, and case-study walkthroughs of sites that improved RAG visibility using the four-dimension methodology.
Each cluster post targets one dimension of RAG SEO at practitioner depth. Together they form the full implementation stack for teams building RAG-optimised content programmes in 2026.
RAG SEO FAQ
What is RAG SEO?
RAG SEO is the practice of optimising content so retrieval-augmented generation systems — like ChatGPT search, Perplexity, and Google AI Overviews — select it as a source for AI-generated answers. It targets the retrieval step specifically, not traditional ranking.
How is RAG different from traditional search?
Traditional search ranks results on a page. RAG retrieves content from an index, passes it to a language model, and generates an answer that synthesises multiple sources — displaying citations rather than sending users to sites. The user may receive your information without ever visiting your page.
Does good SEO automatically work for RAG?
Partially. Strong domain authority, clean technical SEO, and well-structured content improve retrieval probability. But RAG specifically rewards structural clarity and extractability in ways traditional ranking does not — and a page can rank well organically while failing to be retrieved for AI-generated answers.
What’s the most important technical signal for RAG retrieval?
Structured data — specifically FAQPage, QAPage, HowTo, and Article schema. Controlled testing shows FAQPage schema alone improves retrieval citation frequency by 31% compared to identical content without structured markup, because it gives retrieval systems a direct parse path.
Will RAG replace traditional search?
Not in 2026 and likely not entirely in any timeframe. But RAG surfaces already appear alongside traditional results and are taking an increasing share of informational query attention. The more accurate framing: search is now dual-surface — and SEO must serve both.
How do I measure RAG visibility?
Start with manual sampling — track 20–30 target queries weekly across ChatGPT, Perplexity, and Google AI Overviews, recording whether your domain appears in source citations. Supplement with Semrush’s AI Overview tracking, Perplexity’s citation API, and filtered Google Search Console performance reports isolating AI-sourced impressions.
Is it worth optimising for RAG if AI search traffic is small today?
The entities and associations you build with retrieval systems compound. Early investment creates retrieval persistence that becomes harder to displace as AI search volume grows. The question isn’t whether AI search traffic is big enough to matter in 2026. It’s whether you want to be the established source when it is.
Does RAG SEO replace traditional SEO?
No. It adds a second optimisation surface. Strong traditional SEO — rankings, authority, content quality — remains foundational. RAG SEO extends the discipline to cover the retrieval step specifically. The two reinforce each other. You need both.
What RAG SEO Looks Like in Practice
The retrieval-augmented generation shift doesn’t demand a new discipline. It demands an expanded one. The SEO toolkit already contains most of what you need — you’re just applying it to a second surface with different selection logic.
The CARS Framework gives you a structure for that expansion. Citation-worthy structure ensures your content can be extracted cleanly. Authority signals tuned for retrieval — entity association, co-citation, source consistency — get you into the retrieval set. Retrieval-optimised formatting — schema, heading hierarchy, declarative openers — gets you selected from that set. Source persistence tactics — depth, freshness, cross-session relevance — keep you there across follow-up queries.
Here’s what to do next. Take five informational pages currently driving organic traffic. Audit each against the CARS dimensions. Can an AI model extract the core claim from each H2 section without surrounding context? Is schema markup present and accurate? Does the page structure follow the summary-expand pattern, or does it bury the point? Fix the lowest-scoring dimension on each page. Track AI Overview and AI search citation frequency for those pages before and after.
The retrieval shift caught most of the industry watching rankings. You now know what’s happening and what to do about it. The work is applying it before your competitors’ content becomes the model’s default source and your content becomes the one it never retrieves.
The cluster posts covering entity memory, structured data, measurement, content architecture, technical signals, and the full CARS walkthrough will go deeper on each dimension as they go live. Start with the pillar. Then go where your retrieval gaps take you.
References
Google. Generative AI in Search: Expanding AI Overviews and Introducing AI Mode.” Google Blog, March 2026.
https://blog.google/products/search/ai-overviews-march-2026/
Supports: AI Overviews continue expanding as a primary search surface in 2026.OpenAI. Introducing ChatGPT Search.” OpenAI Blog, October 2024.
https://openai.com/index/introducing-chatgpt-search/
Supports: ChatGPT search uses retrieval-augmented generation sourcing from web indexes with attribution.Perplexity AI. How Perplexity Sources and Cites Web Content.” Perplexity Blog, January 2025.
https://blog.perplexity.ai/how-perplexity-sources-content
Supports: Perplexity retrieves from web indexes and displays inline source citations for generated answers.Lewis, Patrick, et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS, 2020.
https://arxiv.org/abs/2005.11401
Supports: Original RAG architecture definition — retrieval step combined with generation step for grounded answers.Semrush. AI Overviews Tracking: New Data on Source Citation Patterns.” Semrush Blog, February 2026.
https://www.semrush.com/blog/ai-overviews-tracking-2026/
Supports: AI Overview source carousels appear frequently on informational queries with measurable citation patterns.Google. Search Quality Rater Guidelines — E-E-A-T Framework.” Google, December 2025.
https://static.googleusercontent.com/media/guidelines.raterhub.com/en//searchqualityevaluatorguidelines.pdf
Supports: Entity association and source authority are core signals in Google’s content quality evaluation.Fishkin, Rand. Zero-Click Search and AI Attribution: 2026 Benchmarks.” SparkToro Blog, January 2026.
https://sparktoro.com/blog/zero-click-search-ai-attribution-2026/
Supports: AI-generated answers reduce click-through rates on source citations for informational queries.Google. How Google Crawls and Indexes the Web.” Google Search Central, 2025.
https://developers.google.com/search/docs/fundamentals/how-search-works
Supports: Crawl budget and content freshness influence which versions of pages enter retrieval indexes.