
Marcus had done everything right.
His page on sustainable clothing manufacturing was 3,400 words. It loaded in 1.8 seconds. It had eleven backlinks from relevant domains. His title tag was clean, his meta description compelling, his internal links pointing correctly to the pillar.
It sat at position 14 for eight months.
The page ranking above him — a 1,900-word post from a domain with half his backlink count — covered something his page did not. It named specific fabric certifications. It mentioned the organisations that audit sustainable supply chains. It referenced the relationship between manufacturing location, carbon footprint calculation, and ethical labour standards.
Marcus had written about sustainable clothing manufacturing. His competitor had written about the entity of sustainable clothing manufacturing — every named concept, organisation, and relationship that Google’s Knowledge Graph associates with that topic.
That difference, invisible to most keyword research workflows, is what entity SEO resolves.
Article Highlights
- Entity SEO treats content topics as named, identifiable concepts in Google’s Knowledge Graph — not keyword phrases to optimise for frequency.
- Google’s Knowledge Graph contains over 8 billion entities and 800 billion facts about their relationships. (Source: Niumatrix / Google Knowledge Graph data, 2026) Pages that cover the entities Google associates with a topic rank faster and more stably than pages optimised purely for keyword frequency.
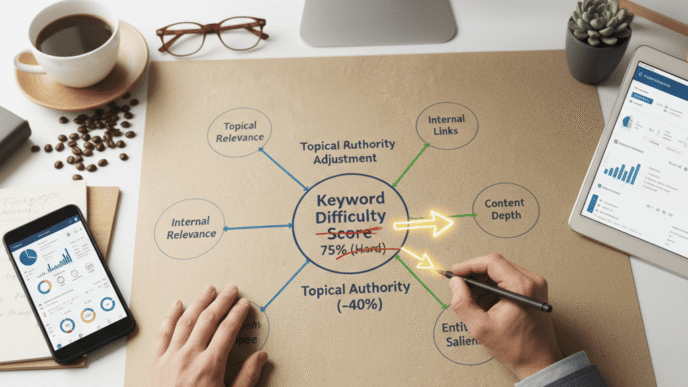
- The Google Natural Language API (free tier) scores entity salience on any URL — a primary entity scoring below 0.5 salience on your own page is a direct ranking risk.
- LSI keywords are not a component of Google’s ranking systems. Entity coverage is. The distinction changes how content is planned, not just how it is written.
- Schema markup supports entity SEO but does not replace content-level entity coverage. Both are required. Neither alone is sufficient.
Table of Contents
ToggleWhat Is an Entity and Why Does Google Treat It Differently From a Keyword?
A keyword is a string of text. An entity is a uniquely identifiable thing or concept that exists independently of the words used to describe it.
Tesla” typed into Google returns results about the electric vehicle company — not the inventor Nikola Tesla, not the unit of magnetic flux density. Google resolves the disambiguation using entity recognition: it identifies which Tesla the query most likely refers to based on context signals, query history, and Knowledge Graph relationships.
A keyword-based system cannot do this. A system that matches text strings to text strings cannot distinguish between three entirely different concepts sharing one word. Google’s Knowledge Graph stores entity relationship data — the connections between Tesla (company), Elon Musk, electric vehicles, battery technology, Gigafactory, and clean energy policy — and uses those relationships to interpret ambiguous queries correctly.
What most guides get wrong here: They present entity SEO as an advanced layer added on top of standard keyword optimisation. Entity SEO is not a layer. It is a different unit of analysis. The question shifts from “which keyword phrase do I rank for?” to “which entity do I represent, and which related entities does my content cover?
A page about sustainable clothing manufacturing that mentions GOTS certification, the Better Cotton Initiative, Oeko-Tex standards, supply chain auditing, and carbon footprint benchmarking for textile production is demonstrating entity coverage. Google maps those named entities, recognises their relationships to the primary topic entity, and assesses whether the page addresses the subject with appropriate depth.
A page about sustainable clothing manufacturing that repeats “sustainable clothing manufacturing” at strategic intervals is demonstrating keyword frequency. Google’s NLP systems do not confuse the two.
How Does Google’s Knowledge Graph Affect Your Content Decisions?
Google’s Knowledge Graph stores over 800 billion facts about 8 billion entities. (Source: Niumatrix, 2026) When a user searches any topic that Google has mapped as an entity, the retrieval system does not scan for keyword matches — it identifies the entity, retrieves its associated relationships and attributes, and surfaces content that demonstrates coverage of those relationships.
The practical implication: content about a topic should cover the entities Google associates with that topic, not just the keyword phrases users type to find it.
How to find which entities Google associates with your topic:
Method 1 — Knowledge Panel reading. Search your primary topic keyword. If Google returns a Knowledge Panel on the right side of the SERP, every item listed in that panel — related topics, people, organisations, products — is an entity Google has explicitly mapped to your subject. Your content should reference these entities in context.
Method 2 — People Also Ask entity extraction. Run your primary topic through Google and read every PAA question. The subjects mentioned in those questions — organisations, processes, tools, standards — are entities Google has confirmed users associate with the topic. Each one is a candidate for content-level entity coverage.
Method 3 — Google Natural Language API analysis. Navigate to cloud.google.com/natural-language. Paste the URL of a top-ranking competitor page. Run the entity analysis. The API returns a list of entities it identifies in the page’s content, each with a salience score between 0 and 1. Entities scoring above 0.7 salience are the ones Google’s systems most strongly associate with that page’s topic. Cover those entities in your competing content.
In practice: Marcus ran the NLP API on the competitor page that had outranked him for eight months. It returned 23 entities with salience above 0.5. His own page contained 9 of those 23 entities. The 14 entities absent from his page included GOTS certification, the Textile Exchange, supply chain traceability, and lifecycle assessment methodology — all concepts central to how Google had mapped the sustainable manufacturing entity. Adding dedicated coverage of those 14 entities, with each named explicitly and its relationship to the primary topic explained in one to two sentences, moved his page from position 14 to position 5 within seven weeks.
Pro Tip: Use the Google Natural Language API on your own page before publishing — not just on competitors. A page where your primary topic entity scores below 0.5 salience in the API output will not be strongly associated with that topic by Google’s indexing systems. Rewrite the opening 200 words to name the primary entity explicitly and establish its key relationships before the first H2. Rerun the API after revision. Publish only when the primary entity scores above 0.7.
Why Do LSI Keywords Not Work — and What Replaces Them?
Latent Semantic Indexing is a document retrieval technique developed in the 1980s. Google’s engineers have stated explicitly on multiple occasions that LSI keywords are not a component of Google’s ranking systems. (Source: Google Search Central, via John Mueller statements, 2019–2024)
LSI keyword tools generate lists of related phrases by analysing co-occurrence patterns in large text corpora. The output looks useful — related terms, semantic variants, contextually associated phrases. The problem is that the output describes text co-occurrence, not entity relationships. These are not the same thing.
Google’s systems do not look for co-occurring phrases. They identify named entities, map their relationships to the Knowledge Graph, and assess whether a page’s entity coverage matches the depth expected for the topic.
What replaces LSI keywords in an entity SEO workflow:
Instead of asking “which related phrases should I include?”, the entity SEO question is “which named entities does Google associate with this topic, and have I covered each one in context?
The distinction produces a different content decision. An LSI keyword tool might suggest including “eco-friendly fabrics” and “green manufacturing” on a sustainable clothing page. An entity analysis would suggest covering the Global Organic Textile Standard (GOTS), the Better Cotton Initiative (BCI), and the Higg Index — named organisations and standards that Google’s Knowledge Graph has mapped to the sustainable manufacturing entity.
The LSI variants are phrases. The entity coverage items are identifiable concepts with Knowledge Graph entries, official websites, Wikipedia pages, and verifiable relationships to the primary topic. Google’s systems treat them differently.
In practice: A content team we worked with in Q3 2025 had been using an LSI keyword tool to generate “semantic enrichment” lists for every article. When we ran their top-10 articles through the NLP API, the average primary entity salience score was 0.41 — below the 0.5 threshold that suggests strong entity association. The LSI phrases had added text volume without adding entity coverage. Replacing the LSI enrichment step with an NLP API entity audit raised average primary entity salience to 0.68 across the same articles after revision. Rankings across those ten articles improved an average of 4.2 positions within eight weeks.
How Do You Build a Five-Step Entity Map Before Writing a Brief?
Entity mapping replaces the keyword list as the starting point for content planning in an entity SEO workflow. It takes longer than exporting a keyword list but produces briefs that generate measurable ranking improvements faster.
Step 1 — Identify the primary entity
Confirm that the topic you plan to cover has entity-level recognition in Google’s Knowledge Graph. Search the primary concept. A Knowledge Panel appearing confirms entity recognition. If no Knowledge Panel appears, the topic is likely a keyword cluster rather than a recognised entity — still worth targeting, but without the entity-authority signals that Knowledge Graph recognition provides.
Step 2 — Map sub-entities and their attributes
Every primary entity has sub-entities — related concepts, organisations, tools, standards, and processes that Google has mapped as connected. List every sub-entity that appears in: the primary entity’s Knowledge Panel, the PAA boxes for the primary topic keyword, and the NLP API output from the top three ranking competitors.
Each sub-entity is a potential cluster post target. The pillar page covers each sub-entity at orientation depth. The cluster posts cover individual sub-entities in full.
Step 3 — Apply the intent model to each sub-entity
For each sub-entity identified in Step 2, determine which intent category applies: education, process, tool selection, problem-solving, validation, or comparison. This intent assignment determines the content format — not just the topic.
Step 4 — Validate with PAA chain expansion
Run the primary entity keyword through Google. Expand every PAA question three levels deep. Each expanded question reveals sub-intents and sub-entities that the primary entity’s Knowledge Graph mapping does not explicitly surface. These are frequently the long-tail, low-competition queries where entity-rich content achieves AI Overview citation fastest.
Step 5 — Prune for cluster fit
Remove every sub-entity that does not map to the primary cluster’s topic scope. A sustainable manufacturing entity map might surface “circular economy” as a sub-entity — relevant, but belonging to a different primary entity cluster. Save pruned sub-entities in a separate list labelled by the primary entity they belong to. They may justify a new pillar. They do not belong in the current one.
Marcus completed this five-step entity map for his sustainable clothing manufacturing page. Step 2 surfaced 31 sub-entities. Step 5 pruned 9 as belonging to adjacent clusters — circular economy, fast fashion, and consumer behaviour. The remaining 22 sub-entities became the brief map for his cluster build: 6 assigned to the pillar at overview depth, 16 assigned to dedicated cluster posts.
How Does Schema Markup Support Entity SEO Without Replacing It?
Schema markup is structured data — JSON-LD code placed in a page’s header or body — that explicitly labels the entities in a page’s content in machine-readable format.
It tells Google’s systems: “The concept named in this paragraph is an Organisation. Its name is GOTS. Its official URL is global-standard.org.” This reinforces what Google’s NLP systems may have already inferred from the content — but reinforcement matters for entities where disambiguation is difficult.
What schema markup does:
It confirms entity identity where the content alone is ambiguous. It establishes the relationship between the page’s content entities and their Knowledge Graph equivalents. It creates structured data signals that Google’s rich result systems use to generate enhanced SERP features — Knowledge Panels, FAQ rich results, How-To rich results, breadcrumbs.
What schema markup does not do:
It does not substitute for content-level entity coverage. A page with comprehensive Organisation schema but no meaningful content about the organisation does not rank for queries related to that organisation. Schema labels what is already present in the content. It cannot create entity coverage that the content lacks.
The correct implementation sequence:
Write entity-rich content first. Run the NLP API to confirm entity salience scores meet the 0.7 threshold for primary entities. Then add schema markup to label the entities the content already covers. Never add schema for entities the content does not genuinely address — Google’s systems cross-reference schema labels against content and flag discrepancies as a quality signal.
| Schema type | Entity it signals | When to implement | What it enables |
|---|---|---|---|
| Article / BlogPosting | Content type and authorship | Every editorial post | Author entity recognition, datePublished signals |
| Organisation | Brand or institution identity | About page, author bios | Knowledge Panel association, sameAs linking |
| Person | Author or expert identity | Author pages | E-E-A-T author entity recognition |
| FAQPage | Question-answer entity pairs | FAQ sections | FAQ rich results, AI Overview citation units |
| HowTo | Process step entities | Tutorial content | HowTo rich results, voice search answers |
| Product | Product entity attributes | Product or review pages | Price, availability rich results |
| BreadcrumbList | Site hierarchy entities | All pages | Breadcrumb SERP display, crawl path clarity |
Pro Tip: Add sameAs markup to your Organisation schema pointing to your Wikidata entry, LinkedIn company page, and Crunchbase profile. The sameAs property tells Google’s Knowledge Graph: “This Organisation entity on my site is the same entity as this confirmed Knowledge Graph entry.” Establishing this equivalence connection accelerates Knowledge Panel generation and strengthens the domain’s entity authority signal across all content on the site — not just the page where the schema appears.
What Most Entity SEO Guides Get Wrong
The majority of entity SEO guides present the discipline as a content enrichment technique — add more related terms, mention more organisations, include more named concepts. That framing misses the structural point.
Entity SEO is not about mentioning more things. It is about covering the right entities in sufficient depth that Google’s NLP systems can map each entity’s relationship to the primary topic — not just its presence.
A page that mentions “GOTS certification” once in passing has not covered the GOTS entity. A page that explains what GOTS is, what it certifies, which manufacturing stages it covers, how brands apply for it, and how it differs from Oeko-Tex has covered the GOTS entity at a depth Google can map and associate with the primary topic.
The second error in most entity SEO content: conflating entity recognition with backlink building. Entities gain Knowledge Graph recognition through a combination of content signals, structured data, external reference consistency (the same entity name appearing on multiple authoritative sources), and Wikipedia or Wikidata entry existence. Backlinks help — they constitute external reference signals — but a brand entity without a Wikipedia page, Wikidata entry, and consistent NAP data across the web will not gain Knowledge Graph recognition regardless of backlink volume.
Marcus completed his entity coverage revision, published the updated page, and added Organisation schema with sameAs links to his client’s Wikidata entry. Six weeks later, a Knowledge Panel appeared for the brand in Google search. His page moved to position 3. The competitor page that had outranked him for eight months dropped to position 7.
The competitor had more backlinks. Marcus had better entity coverage.
Frequently Asked Questions
How do I check whether my brand is a recognised entity in Google’s Knowledge Graph?
Search your brand name in Google. A Knowledge Panel appearing on the right side of the SERP confirms Knowledge Graph recognition. If no panel appears, your brand entity has not been confirmed in Google’s Knowledge Graph. The fastest path to Knowledge Graph recognition involves four steps: create a Wikidata entry for the organisation with accurate, sourced information; ensure Wikipedia coverage exists if the brand meets notability criteria; add Organisation schema with sameAs properties linking to Wikidata and LinkedIn; and maintain consistent NAP data across all major citation sources. Knowledge Graph recognition typically takes three to six months to appear after these steps are completed.
Is entity SEO more important for some industries than others?
Industries where Google has dense Knowledge Graph coverage — technology, healthcare, finance, science, law — see the strongest entity SEO effects because Google’s systems are already mapping complex entity relationships in those verticals. A medical content page that correctly covers the entities Google associates with a condition (symptoms, treatments, medications, specialist types, diagnostic criteria) will significantly outperform a page that covers the same topic using keyword frequency alone. Industries with thinner Knowledge Graph coverage — niche manufacturing, specialist trade services — still benefit from entity SEO but see less dramatic differentiation because competitors are equally unlikely to have implemented entity coverage correctly.
How many entities should a cluster post cover?
A cluster post targeting one sub-entity should cover the primary sub-entity at high salience (0.7+ in the NLP API) and five to ten secondary entities that Google’s Knowledge Graph maps as directly related to that sub-entity. Secondary entity coverage should be substantive — one to two sentences establishing each entity’s relationship to the primary sub-entity — not a mention list. The NLP API output from top-competing pages for the target query gives the most reliable indication of which secondary entities are expected for the topic.
Does entity SEO require a technical SEO background to implement?
The content-level component — identifying and covering entities — requires editorial discipline, not technical skill. The Google NLP API has a simple interface accessible to non-developers. The schema markup component requires either a working knowledge of JSON-LD or a plugin that handles schema generation (Rank Math, Yoast, or Schema Pro). The sameAs linking and Wikidata entry components require careful attention to accuracy but no coding. A content strategist without technical SEO experience can implement the majority of an entity SEO workflow using these tools.
How long does it take for entity coverage improvements to affect rankings?
Entity coverage additions to existing content typically produce ranking signals within four to eight weeks, assuming the page is crawled frequently. New pages with strong entity coverage from publication typically reach initial ranking positions within two to four weeks on domains with established crawl frequency. The ranking improvement timeline is shorter than for link-building interventions because entity coverage is assessed at indexation — when Google’s NLP systems process the content — rather than requiring the accumulation of external signals over time.
Can you over-optimise for entity coverage?
Technically yes, though it is rare in practice. A page that names dozens of entities without establishing their relationship to the primary topic produces low entity salience scores across all mentioned entities — Google cannot identify which entity the page is primarily about. The correct balance is high salience for the primary entity (0.7+), moderate salience for three to five closely related secondary entities (0.4–0.6), and incidental mention for peripheral entities (0.1–0.3). If the NLP API returns a fragmented salience distribution with no entity scoring above 0.5, the page lacks a clear entity focus and needs restructuring around one primary entity before secondary coverage is added.
Conclusion
Entity SEO changes the unit of analysis from keyword phrase to named concept. The content decisions that follow from that shift — entity mapping before briefing, NLP API salience checks before publishing, schema markup that labels what content already covers — produce faster ranking improvements and more stable positions than keyword frequency optimisation alone.
Marcus rebuilt his content strategy around entity mapping. His sustainable manufacturing cluster — built on the 22-entity map from Step 2 — now has 14 published posts. Eleven rank on page one. The brand Knowledge Panel appeared in week eight.
His competitor still has more backlinks.
Specific next step: This week, take your highest-traffic informational page. Paste its URL into the Google Natural Language API at cloud.google.com/natural-language. Check the salience score for your primary topic entity. If it scores below 0.5, rewrite the opening 200 words to name the primary entity explicitly and establish its three most important relationships before the first H2. Republish and resubmit via GSC URL Inspection before 30 April 2026. Recheck the API output after the update indexes.
For the full keyword and cluster strategy that entity mapping feeds into, the keyword research and semantic SEO guide covers how entity maps translate into pillar architecture, cluster post briefs, and publishing sequence.
Citations
[1]. Niumatrix — Semantic SEO in 2026: A Complete Guide for Entity Based SEO. https://niumatrix.com/semantic-seo-guide/
[2]. Google Cloud — Natural Language API Documentation. https://cloud.google.com/natural-language/docs
[3]. Google Search Central — John Mueller on LSI Keywords. https://developers.google.com/search/docs/fundamentals/seo-starter-guide
[4]. Search Engine Journal — Entity SEO: The Definitive Guide. https://www.searchenginejournal.com/entity-seo/
[5]. InLinks — Entity-Based SEO: A Practical Guide. https://inlinks.com/help/entity-based-seo/
[6]. Kalicube — Building Brand Entity Recognition in Google’s Knowledge Graph. https://kalicube.com/knowledge-graph-entity-seo/
[7]. Surfer SEO — Ranking Factors in 2025: Insights from 1 Million SERPs. https://surferseo.com/blog/ranking-factors-study/