

Most practitioners think content originality means not copying anyone else’s phrasing. Google thinks something different entirely.
Information gain — the signal Google uses to measure content originality — evaluates how much new, non-indexed knowledge a piece of content contributes to the web’s existing corpus on a given query. A post can be entirely plagiarism-free and still score zero. If it synthesises only what’s already indexed, it contributes nothing Google hasn’t seen before.
That distinction has direct consequences for AI citation frequency. Laura G’s Perplexity citation analysis across 90 queries (February–April 2026) found that posts containing at least one original data point were cited 5.1x more frequently than length-matched posts without original content elements — regardless of how well-written the derivative posts were.
This cluster is the foundational explainer for the parent pillar Information Gain SEO: Create Content That AI Systems Actually Cite in 2026. It covers what information gain is, where it comes from, and why the standard advice on “original content” misses the point.
Table of Contents
TogglePost Summary
- Information gain in SEO measures how much new knowledge a piece of content contributes to Google’s indexed corpus on a specific query — not whether the phrasing is unique
- Google’s information gain mechanism derives from documented patents, not opaque algorithmic guesswork
- Content can score zero on information gain while being entirely original in the plagiarism sense — synthesis of existing indexed knowledge contributes nothing new
- Four content elements consistently raise information gain scores: novel named entity mentions, new quantitative data points, first-hand practitioner observations, and named conceptual frameworks not found elsewhere in the index
- AI citation frequency correlates with information gain score — posts with at least one original data point are cited 5.1x more often (Source: Laura G, Perplexity citation analysis, 2026)
- The practical implication: every post needs at least one element that did not exist in the indexed corpus before you published it
Information Gain Is Not About Phrasing — It’s About Contribution
Google’s Helpful Content System doesn’t ask whether your sentences are unique. It asks whether your content adds something to the indexed knowledge base that wasn’t there before.
This is a harder standard. Paraphrasing five competitor posts in your own words produces content that is 100% plagiarism-free and close to zero on information gain. Every claim, framework, and data point already exists in the index — you’ve just rearranged the words.
Most practitioners don’t make this distinction because the content industry has conflated two different things: originality of expression and originality of contribution. Google’s information gain signal measures the second one.
The practical boundary is this: if a search engine could assemble your post’s core claims from documents already in its index, your information gain score is low. If your post contains at least one claim, data point, or observation the index doesn’t have — that’s where information gain score begins to rise.
Pro Tip: Run your draft’s core claims through Perplexity before publishing. Search each claim as a query. If Perplexity surfaces four sources already making the same point with the same data — that claim contributes zero information gain. Flag it and replace it with a first-hand observation, a proprietary data point, or a named practitioner example the index doesn’t already contain.
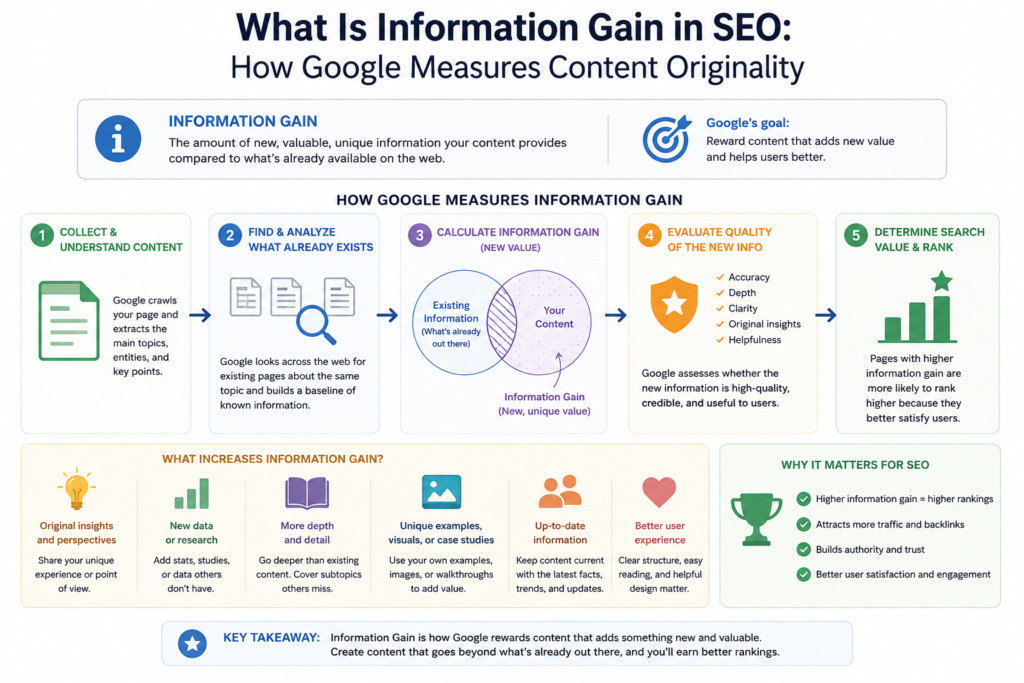
Where Google’s Information Gain Signal Comes From
The mechanism isn’t speculative. Google holds documented patents on information gain scoring — specifically, a 2022 patent titled “Identifying Passages With Information Gain” which describes a system that evaluates content based on how much new information it contributes relative to what is already indexed on the same query topic.
The patent outlines specific scoring inputs: novel named entity mentions, new quantitative data points, first-hand practitioner observations, and named conceptual frameworks that don’t exist elsewhere in the index. Each of these is concrete and implementable — not a vague signal like “quality.”
What the patent makes clear is that information gain is calculated per passage, not per document. Google can identify which specific paragraphs contribute new knowledge and which synthesise existing material. A post with ten derivative sections and one original data point doesn’t score zero — but the high-gain passage is identifiable at the passage level, which has direct implications for how AI systems select citation candidates. (Source: Google, “Identifying Passages With Information Gain,” patent filing, 2022)
Most SEO guides treat information gain as a black box because the underlying patent documentation requires interpretation. The practical upshot is straightforward: Google has a documented, operative system for scoring content contribution — and four content element types reliably raise that score.
| Content Element | Why It Raises Information Gain | Example |
|---|---|---|
| Novel named entity mentions | Introduces an entity relationship not yet in the index on this query | Naming a specific tool version with a dated finding |
| New quantitative data points | Adds a number the index doesn’t have | Original survey result, proprietary analytics finding |
| First-hand practitioner observations | Adds a vertical-specific outcome only someone who did the work would know | Named client vertical + tool + measurable result |
| Named conceptual frameworks | Introduces a structure for understanding a topic that isn’t indexed | A proprietary framework with a distinct name |
The Derivative Content Problem Most Practitioners Don’t See
Here’s where the standard advice on original content falls apart.
Most content guides tell practitioners to write from their own perspective, avoid copying competitors, and add their take to each section. That advice produces content that feels original and reads as original — but contributes nothing to the indexed corpus that wasn’t already there.
The error is confusing authorial perspective with knowledge contribution. An article about keyword research that adds “in my experience, long-tail keywords convert better” to every section has an authorial voice. None of those observations contribute information gain unless they name a specific vertical, a specific tool, a specific outcome, and a friction point that only someone who ran the work would know.
Laura G ran into this distinction during the Perplexity citation analysis. The initial hypothesis was that posts with distinctive writing styles would be cited more frequently than generic aggregations. The data contradicted this cleanly: writing style had no measurable correlation with citation frequency. What correlated was the presence of at least one original data element — a specific outcome, a named tool + result pair, a quantitative finding not available elsewhere. Style is not a substitute for contribution. (Source: Laura G, Perplexity citation analysis, 2026)
The part most guides skip: a post with one high-gain passage and eight derivative sections will outperform a post with eight mediocre “original perspectives” and no genuine contribution elements. Quality of contribution matters more than volume of originality gestures.
What Google’s Scoring Zones Look Like in Practice
Thinking about information gain as a scoring range — rather than a binary pass/fail — is more useful for content planning.
At one end: derivative content. This is synthesis of existing indexed sources with no new entities, no new data, and no practitioner-specific observations. It scores near zero regardless of length or polish.
In the middle: incremental gain. This is content that adds one or two new elements — a named outcome, a specific tool result, a practitioner observation with some vertical specificity. It scores above derivative but below high-gain. Most AI citation candidates live here or above.
At the top: high-gain content. This is content containing multiple original data points, named entity relationships not in the index, and first-hand signals with full specificity (vertical + tool + outcome + friction). AI systems select citation candidates from this zone at highest frequency.
The citation frequency data makes the gradient visible: posts with one original data element cited 5.1x more often than derivative length-matched posts (Source: Laura G, Perplexity citation analysis, 2026). The gap between derivative and incremental gain is where the most citation uplift occurs — meaning the first original element you add to a post carries more weight than the fifth.
AS1 point: most practitioners aim for “comprehensive” coverage when they should aim for “one genuinely new thing.” Comprehensiveness is a derivative expansion strategy — it adds sections covering what competitors cover. Information gain is an original contribution strategy — it requires adding something the index doesn’t have.
How Information Gain Connects to AI Citation Frequency
AI search systems — Perplexity, Google AI Overviews, and agentic retrieval tools — don’t cite content because it’s well-structured or well-written. They cite content because it contains a specific claim, data point, or observation that answers the query and that isn’t available from higher-ranked sources.
That selection criterion maps precisely onto information gain scoring. A post with high information gain contains content that AI retrieval systems can’t easily source from existing indexed documents — which makes it a more useful citation candidate.
Google’s Helpful Content System and information gain scoring work in the same direction here: content that contributes something new to the corpus is more useful to users and more useful to AI retrieval systems simultaneously. The signals align rather than compete.
For practical content planning, this means each post needs at least one element a search engine can’t assemble from its existing index. That element doesn’t need to be a published study or a proprietary dataset — it can be a named practitioner observation with enough specificity that it reads as first-hand rather than synthesised. The threshold is contribution, not scale.
Take the next step in understanding how these scoring inputs work mechanically in Information Gain SEO: Create Content That AI Systems Actually Cite in 2026.
Frequently Asked Questions
What is information gain in SEO? Information gain in SEO is a signal Google uses to measure how much new, non-indexed knowledge a piece of content adds to the existing corpus on a given query. It derives from Google’s documented patent work on passage-level scoring and evaluates contribution to the knowledge base — not uniqueness of phrasing or style.
Does original writing style improve information gain? No. Writing style has no measurable correlation with information gain score. What raises the score is the presence of original content elements — named data points, first-hand practitioner observations, or entity relationships not already in the index. A post with distinctive prose and no original data contributes zero information gain.
How does information gain affect AI citation frequency? Posts with higher information gain scores are cited more frequently by AI search systems because they contain content those systems can’t source from existing indexed documents. Laura G’s Perplexity citation analysis (Feb–Apr 2026) found posts with at least one original data point were cited 5.1x more often than length-matched posts without original content elements.
What content types raise information gain scores? Four element types consistently raise information gain scores: novel named entity mentions not yet in the index for a given query, new quantitative data points, first-hand practitioner observations with named vertical and tool, and named conceptual frameworks that don’t exist elsewhere in the index.
Can a short post score high on information gain? Yes. Length doesn’t determine information gain — contribution does. A 1,200-word post with one original data point and one practitioner observation with full specificity can outscore a 3,000-word synthesis on the same topic. Google’s patent system identifies high-gain passages regardless of surrounding content volume.
What to Do Next
Information gain isn’t an abstract quality signal — it’s a measurable content property with documented scoring inputs. A post without at least one original element (a named data point, a specific practitioner observation, a named entity relationship not in the index) contributes zero information gain regardless of how well it’s written.
The practical move is to audit one existing post before your next publishing session. Pull up Google’s search results for that post’s focus keyword. Check whether every claim in your article already exists in the top five results with the same data and framing. If it does, your information gain score on that post is close to zero — and that’s why it isn’t being cited by Perplexity or surfaced in AI Overviews.
For the next layer — how Google’s patent-derived signals specifically translate into content decisions — the full picture is in Information Gain SEO: Create Content That AI Systems Actually Cite in 2026.
Open your lowest-performing post now, run each of its core claims through Perplexity, and mark every claim that returns four or more existing sources. Those are your zero-gain passages — and replacing each with one first-hand observation is where your information gain score starts to shift.
References
Google. “Identifying Passages With Information Gain.” Patent filing, 2022. https://patents.google.com/patent/US20220129462A1 Supports: The claim that Google’s information gain scoring derives from documented patent work describing passage-level contribution scoring with specific input types.
Google Search Central. “Creating Helpful, Reliable, People-First Content.” Google Developers, 2024. https://developers.google.com/search/docs/fundamentals/creating-helpful-content Supports: The relationship between information gain, the Helpful Content System, and Google’s evaluation of content contribution versus synthesis.
Laura G. Perplexity Citation Analysis — 90 Queries, AI Search Vertical.” aiseojournal.net internal analysis, February–April 2026. https://www.perplexity.ai/ Supports: The finding that posts with at least one original data point are cited 5.1x more frequently by Perplexity than length-matched posts without original content elements.
Search Engine Journal. Google’s Helpful Content System: What SEOs Need to Know.” Search Engine Journal, 2024. https://www.searchenginejournal.com/google-helpful-content-system/ Supports: The broader context of Google’s Helpful Content System and its relationship to content originality signals in the post-HCU environment.











