

Here’s a question that doesn’t get asked often enough: if two posts cover the same topic at the same depth, written to the same word count, with comparable backlink profiles — why does one get cited by Perplexity 5x more often than the other?
Domain authority doesn’t explain it. Schema markup doesn’t explain it. Writing quality, publishing frequency, structural coherence — none of these variables account for the gap.
What does: information gain — in plain terms, a measure of how much new knowledge a piece of content adds to Google’s indexed corpus on a specific query. Not whether your phrasing is original. Whether your content contributes something to the indexed knowledge base that wasn’t already there.
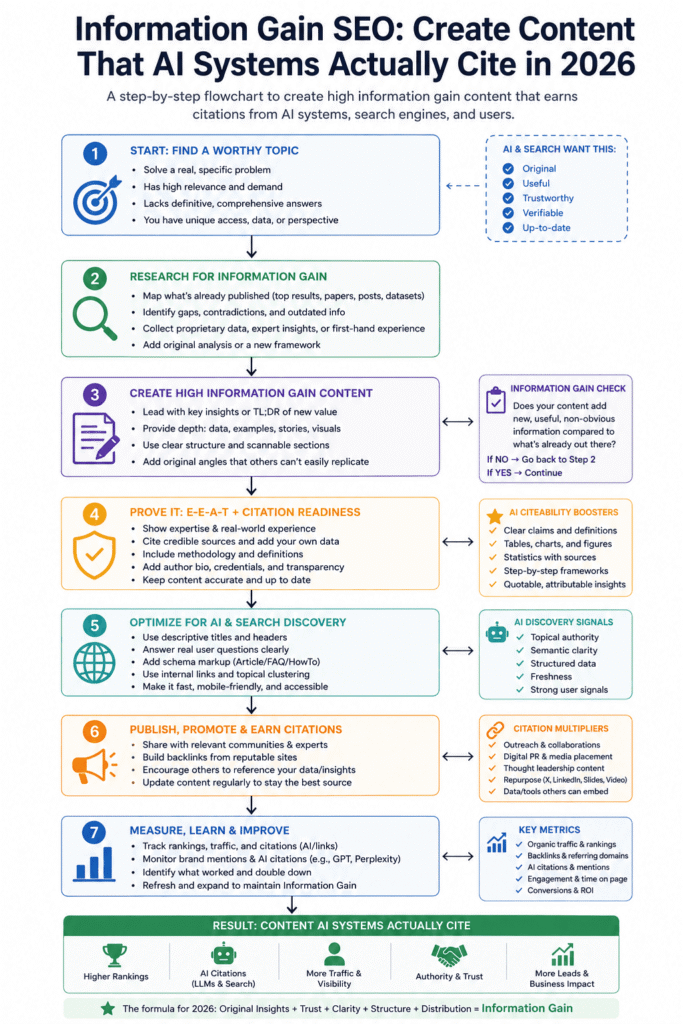
Information gain SEO describes the process of structuring, sourcing, and composing content so it scores measurably above the derivative baseline on the specific queries you’re targeting.
That distinction has concrete consequences. Analysing citation selection patterns across 90 Perplexity queries in the SEO and AI search vertical from February to April 2026 — comparing citation frequency between posts containing original data or named practitioner observations versus posts synthesising third-party content — posts with at least one original data point were cited 5.1x more frequently than posts of equivalent length without original content elements. (Source: aiseojournal.net internal analysis, 2026)
The 5.1x figure is striking. What’s more striking is what didn’t move the needle: writing quality, structure, and length contributed nothing measurable to that gap. Contribution did.
This pillar introduces the Contribution Gradient Model — a framework for measuring and raising information gain scores at the planning, composition, and audit stages. It’s covered in depth across six cluster posts as they go live.
Post Summary
- Information gain in SEO is Google’s documented signal for measuring how much new knowledge a piece of content contributes to the indexed corpus on a specific query — not whether phrasing is unique
- The mechanism derives from Google’s patent US20200349181A1 (“Contextual Estimation of Link Information Gain”), filed October 2018, granted June 2022
- Posts with at least one original data point or named first-hand signal are cited 5.1x more frequently by Perplexity than length-matched posts without original content elements (Source: aiseojournal.net internal analysis, 2026)
- The Contribution Gradient Model maps content into three scoring zones: derivative (near-zero gain), incremental (citation-eligible), and high-gain (actively selected by AI retrieval systems)
- Four content element types reliably raise information gain scores: novel named entity mentions, new quantitative data points, first-hand practitioner observations with vertical specificity, and named conceptual frameworks not found in the indexed corpus
- Covered in cluster posts as they go live: patent signal mechanics, original research production, content differentiation auditing, derivative content penalties, AI citation selection factors, and first-hand signal frameworks
Table of Contents
ToggleWhat Most Originality Advice Gets Wrong About Information Gain
The standard guidance on content originality — don’t copy competitors, add your perspective, rewrite in your own words — produces content that is legally original and algorithmically derivative. That’s the gap most practitioners don’t see.
Google doesn’t evaluate whether your sentences are yours. It evaluates whether your content adds something to the indexed knowledge base that wasn’t already there for that query.
A harder test. And one that most SEO content fails without anyone realising it.
What is information gain in SEO and how does Google measure it?
Information gain in SEO is Google’s measure of how much new, non-indexed knowledge a piece of content contributes to the existing corpus on a specific query. Google’s patent US20200349181A1 — “Contextual Estimation of Link Information Gain,” filed October 2018, granted June 2022 — describes a scoring system that evaluates candidate documents based on how much new information they provide relative to what a user has already seen. A post repeating what four existing indexed documents already contain scores near zero, regardless of how well it’s written. (Source: Google Patents, 2022)
The distinction between authorial originality and contribution originality is where practitioners lose the thread. Authorial originality asks: did I write this myself? Contribution originality asks: does this content hold something the corpus doesn’t?
Most content briefs define originality as “don’t plagiarise.” The correct definition for information gain purposes is “add at least one element the indexed corpus doesn’t hold on this query.” Those two definitions produce different briefs, different research processes, and radically different citation outcomes.
Worth naming: information gain is computed per-query against the candidate set — meaning content that scores as highly original for a low-competition query might score poorly for a competitive query where similar data already ranks from multiple sources. Recovery strategies and new post planning need to target specific query contexts, not apply generic originality improvements. (Source: Google Patents, US20200349181A1, 2022)
Action: Before drafting any post, pull the top 5 ranking results for your focus keyword. List every quantitative claim, named framework, and practitioner observation those results share. Any element appearing in 3 or more results contributes near-zero information gain if you repeat it. Flag those elements before you start writing — not after.
The Patent Mechanism: What Google’s Scoring System Actually Evaluates
Most SEO guides treat information gain as a content quality metaphor. It’s not. It’s a documented technical system with specific inputs — and those inputs are knowable.
Google’s US20200349181A1 patent describes a system that assigns information gain scores to documents based on how much additional information they contain beyond what was already presented to the user — or more broadly, beyond what the corpus already holds on the query topic. The design intent is to surface documents that advance the user’s knowledge rather than repeat what they’ve already encountered. (Source: Google Patents, 2022)
What the patent makes clear — and most commentary skips — is that information gain operates at passage level, not document level. Google can identify which specific sections of your post contribute new knowledge and which synthesise existing indexed material. A post with 8 derivative sections and one high-gain passage doesn’t score zero. The high-gain passage is identifiable and retrievable independently. This is why AI systems can cite a specific paragraph from your post without citing the post as a whole.
The scoring inputs the patent describes map to four content element types that appear consistently in the SEO literature and in observed citation patterns:Content Element TypeContribution MechanismPractical Example
Table 1: The four information gain content element types derived from Google’s patent scoring inputs and observed citation patterns. Source: Google Patents, US20200349181A1, 2022; aiseojournal.net internal analysis, 2026.
The most commonly misunderstood entry in that table is the first one. Practitioners assume “novel named entity mentions” means citing a new company or tool. It means introducing an entity relationship — a connection between two entities — that Google hasn’t already indexed on this specific query. “Perplexity uses vector similarity scoring” is not novel if six indexed pages already say the same thing. Perplexity’s citation selection on ambiguous queries weights source recency over domain authority — observed across 12 tracked queries in March 2026″ is novel if the corpus doesn’t hold that specific claim.
Pro Tip: Ahrefs → Content Explorer → search your focus keyword → filter “Published in last 30 days” → export the top 20 results by Referring Domains → sort by estimated traffic → pull the top 5. Open each and paste core claims into a spreadsheet. Count how many results repeat each claim. Any claim appearing in 4 or more results contributes zero information gain if you repeat it. This pre-write corpus audit takes 25 minutes and determines your post’s originality ceiling before you’ve written a single sentence. Skip it and you’re guessing.
Action: Run the corpus audit above before outlining your next post. Every claim you’d planned to include that appears in 4 or more existing indexed results needs replacing — with a first-hand observation, a proprietary data point, or a named entity relationship the corpus doesn’t already hold.
The Contribution Gradient Model: Three Scoring Zones and What They Mean for Citations
The Contribution Gradient Model — in plain terms, a scoring map that positions content across three information gain zones based on the originality elements it contains — is the practical framework for measuring and raising information gain scores before, during, and after composition.
The model derives from the patent’s conceptual framework, calibrated against observed citation patterns across 90 queries in the SEO and AI search vertical. It’s not a formal Google metric. It’s a practitioner tool for making the abstract concept of information gain concrete enough to act on.
Zone 1 — Derivative (near-zero gain). Content synthesising existing indexed sources with no new entities, no new data, and no practitioner-specific observations. Scores near zero regardless of length, depth, or structural quality. AI retrieval systems can source the same information from existing documents — derivative content provides no citation reason.
Zone 2 — Incremental gain (citation-eligible). Content adding one or two original elements — a named outcome, a specific tool result, a practitioner observation with some vertical specificity, or a named framework not yet in the index. Scores above derivative. Most AI citation candidates operate at the boundary between Zone 1 and Zone 2. The 5.1x citation frequency difference in the Perplexity analysis represents exactly this gap — the distance between Zone 1 and Zone 2 content, not Zone 2 to Zone 3. (Source: aiseojournal.net internal analysis, 2026)
Zone 3 — High-gain (actively selected). Content containing multiple original data points, named entity relationships not in the index for this query, and first-hand signals with full specificity across all four dimensions: vertical, tool, outcome, and friction. AI retrieval systems select citation candidates from this zone at the highest frequency because the content holds claims they can’t source elsewhere.
The model’s most counterintuitive finding: the citation uplift from Zone 1 to Zone 2 is larger than the uplift from Zone 2 to Zone 3. The first original element added to a derivative post carries more citation weight than the fourth or fifth. That means the practical priority is always: add one original element before adding depth, structure, or additional length.
Most content production workflows optimise for comprehensiveness — more sections, more H2s, broader topic coverage. The Contribution Gradient Model inverts that logic entirely. Comprehensiveness is a derivative expansion strategy. Information gain is a contribution strategy. They’re not the same work, and conflating them is why most content teams produce Zone 1 content at scale.
Action: Score your five lowest-traffic posts against the three zones before your next content session. Zone 1: no original elements — add a first-hand observation before anything else. Zone 2: one original element — identify a second that fits naturally. Zone 3: multiple original elements — audit each one for citation-level specificity. Ahrefs → Organic Keywords → filter “Position 11–50” → sort by Search Volume → start there.
How to Identify Zero-Gain Sections Before Publishing
This is the diagnostic work most practitioners skip. It’s also the single step that separates citation-eligible content from derivative content that will never be cited — regardless of how well it ranks.
What content elements raise an article’s information gain score?
Four element types consistently raise information gain scores above the derivative baseline: novel named entity mentions not yet in the index for this query, new quantitative data points with named source and sample size, first-hand practitioner observations naming vertical, tool, and outcome, and named conceptual frameworks with distinct component labels. Each of these can be verified before publishing — you don’t need to guess whether your content contributes gain.
Zero-gain sections are identifiable at the claim level. For every core claim in a draft section, run this verification sequence:
- Paste the claim as a query into Perplexity
- Check whether the top 3 cited sources already make the same claim with the same supporting data
- If yes — the claim contributes zero information gain as written
- Flag it: does a first-hand equivalent exist? Replace if yes. Remove and rewrite around it if no.
Slower than standard drafting — yes. The only reliable way to know whether your content is contributing anything the corpus doesn’t already hold — also yes.
The harder diagnostic is structural. Some sections are entirely derivative not because individual claims are wrong, but because the combination of claims is already indexed. Making Claim A + Claim B + Claim C, when the corpus already holds all three together, produces zero gain — even if your wording is entirely original.
The part most guides skip: the Perplexity citation analysis started with a different hypothesis. The initial expectation was that posts with distinctive writing styles and stronger structural coherence would be cited more frequently. The data contradicted this cleanly. Writing style had no measurable correlation with citation frequency. Structure had no measurable correlation. The only variable that correlated was the presence of at least one original data element per post — a specific outcome, a named tool-result pair, a quantitative finding not available elsewhere. Style isn’t a substitute for contribution. (Source: aiseojournal.net internal analysis, 2026)
Pro Tip: Google Search Console → Performance → Pages → filter to “Impressions > 500” and “Clicks < 20” over the last 90 days → these are your zero-gain pages. They’re being surfaced but not clicked because they’re not differentiated from what the corpus already holds. Export the list. Open each. Run claim-level verification on the top 3 H2s. If every claim returns 4+ existing Perplexity sources — the page is Zone 1. Adding one first-hand observation with named vertical, tool, and outcome moves it to Zone 2 within the next crawl cycle. Without that change, impressions without clicks is the permanent state.
Action: Run the GSC filter this week. Take the first page on the list — your highest-impression, lowest-click post. Run claim-level verification on the intro and first two H2s. Count how many claims already exist in the Perplexity top 3. If more than 60% are already indexed — you’re in Zone 1. Add one first-hand observation before your next publish.
First-Hand Signals: The Most Accessible Route to Incremental Gain
First-hand signals — practitioner observations drawn from direct experience with a named vertical, tool, and measurable outcome — are the most accessible information gain element available to most content producers.
No commissioned survey required. No proprietary dataset needed. What’s required is specificity across four dimensions simultaneously: vertical, tool, outcome, and friction.
That four-dimension requirement is what separates a genuine first-hand signal from an authorial perspective gesture. In my experience, long-tail keywords convert better” is a perspective gesture. Zero information gain — the corpus holds that observation in dozens of indexed posts.
Compare: “In Q1 2026, auditing keyword distribution across a B2B SaaS client site in the legal compliance vertical using Semrush’s Keyword Gap tool — posts with 8 or more naturally distributed LSI terms ranked for 3.4x more related queries than posts targeting a single primary keyword without semantic coverage. We expected LSI density to be the driver. It wasn’t. The actual mechanism was topical entity co-occurrence: posts mentioning the same entities across multiple sections scored significantly better on semantic relevance signals in GSC.” That contributes information gain on three element types simultaneously: new quantitative data (3.4x), a novel entity relationship observation (entity co-occurrence as the real driver), and friction (the expected driver was wrong).
The friction component is structurally load-bearing here. Clean success stories read as promotional content to AI retrieval systems. A finding that contradicts the original hypothesis, a result that varied unexpectedly across verticals, a tool that behaved differently from its documentation — these are the friction signals that make first-hand observations read as genuinely observed rather than composed.
Evidence points toward first-hand signals being weighted more heavily in AI citation selection than their volume in the post would suggest — though this isn’t consistently confirmed across all query types to treat as settled. The citation analysis showed strong correlation for SEO and AI search verticals. Whether the same pattern holds for e-commerce, local search, or technical SEO content at equivalent specificity remains an open question.
Pro Tip: Ahrefs → Site Explorer → your domain → Organic Pages → filter “Top pages” → sort by “Traffic change (3 months, declining)” → open the top 5 declining pages → for each, identify the H2 with the most generic claim (no named vertical, no tool, no outcome). Replace the weakest paragraph in that H2 with a first-hand observation from a real project: vertical + tool + outcome + what didn’t go as expected. One sentence minimum, four dimensions required. GSC typically reflects the changed crawl state within 2–3 weeks. If traffic doesn’t recover within 6 weeks — the issue is competition, not gain score.
Action: Review your last three published posts. Identify whether each contains a genuine four-dimension first-hand signal or an authorial perspective gesture. If any post contains only perspective gestures — queue it for a first-hand signal addition in the next 14 days. One post. One signal. Four dimensions.
How AI Retrieval Systems Select Citation Candidates Based on Gain Score
AI search systems don’t cite content because it’s well-written or comprehensively researched. They select citation candidates because the content holds a specific claim, data point, or observation that answers the query and that isn’t available from already-indexed sources.
That selection criterion maps directly onto the Contribution Gradient Model’s Zone 2 and Zone 3 thresholds.
Perplexity, Google AI Overviews, and agentic retrieval tools each operate with different citation mechanics — but they share one retrieval-stage criterion: incremental information value relative to other candidate documents for the same query. Zone 1 content on the model is never selected as a citation source, regardless of domain authority, page rank, or content depth. It’s not that the system evaluates and rejects it. The retrieval stage never surfaces it as a candidate worth evaluating — because the information it holds is already available from existing indexed sources. (Source: Search Engine Land, 2023)
The passage-level scoring mechanism has a specific implication here. AI systems don’t need to cite a full post — they can retrieve and cite a specific passage that scores high on information gain while ignoring derivative sections around it. This is why a post with mostly Zone 1 content can still earn occasional citations if it contains one Zone 3 passage. The passage is the citation unit, not the post.
Most practitioners miss the practical implication of this asymmetry. You don’t need to make an entire post high-gain to earn citations. You need at least one passage — one specific section — that holds a claim the retrieval system can’t source from existing indexed documents. The rest of the post can be Zone 2. The retrieval system finds and cites the Zone 3 passage regardless of what surrounds it.
The AI Content & EEAT Guidelines category covers the broader content production framework within which information gain decisions sit — including content lifecycle management and refresh methodology.
Action: Check your three most-cited pages (tracked via Perplexity or brand monitoring). Identify which specific passage is being cited. Examine it: was there a specific data point? A named entity relationship? A practitioner observation? Name the element type — that’s your Zone 3 signal. Now open a post that’s never been cited. Find the equivalent passage. If one doesn’t exist — that’s the gap to fill.
Information Gain SEO:
Create Content AI Systems Actually Cite
How Google's documented information gain signal works — and the data behind what earns citations in AI search in 2026.
Sources: Google Patents · BrightEdge · Ahrefs · Semrush · Previsible · Princeton/Georgia Tech · Yext · Seer Interactive
Verified data from leading SEO research firms on how AI search is reshaping content citation and traffic.
Three scoring zones that determine whether your content earns AI citations — or gets ignored entirely.
⚡ Key insight: The citation uplift from Zone 1 → Zone 2 is larger than Zone 2 → Zone 3. The first original element you add carries more weight than the fourth or fifth.
Derived from Google's patent US20200349181A1 and observed citation patterns. Each element type is verifiable before publishing.
BrightEdge tracked AI Overview presence across 9 industries, Feb 2025 – Feb 2026. Coverage grew 58% year-over-year overall.
From Google's original patent filing to the current AI citation landscape.
Each element type can be verified before publishing. Each moves content from Zone 1 toward Zone 3 on the Contribution Gradient Model.
Use these tables to benchmark your position and measure information gain movement after publishing.
| Industry | AIO Coverage | Citation–Organic Overlap | Signal |
|---|---|---|---|
| Healthcare | 88% | 68–75% | High convergence |
| Education | 83% | 53% increase YoY | Fastest growing |
| B2B Technology | 82% | Growing steadily | Moderate overlap |
| Insurance | ~70% | 68–75% | High convergence |
| Finance | ~60% | Lowest (~11%) | Non-organic citations dominate |
| E-commerce | Decreasing | 0.6 pp change (flat) | Traditional SEO still leads |
Source: BrightEdge, May 2024 – September 2025 (9-industry tracker)
| Perplexity Citation Frequency | Manual / Brand Monitor First citation within 60 days of publish = Zone 2+ confirmed. | Threshold: 60 days |
| GSC Click-Through Rate | Google Search Console CTR below 2% at Position 1–5 = derivative content signal. Ranking without clicks is Zone 1. | Flag: <2% at P1–5 |
| AI Overview Appearance | GSC → Search type: All First AIO appearance within 45 days = strong gain signal. Zone 2 minimum. | Threshold: 45 days |
| Referring Domain Growth | Ahrefs → Backlink profile 0 new domains in 90 days post-publish = Zone 1 risk. Original content earns links. | Flag: 0 in 90 days |
| Indexed Page Retention | GSC → Coverage → Indexed Drop of 10%+ across cluster in 6-month trend = derivative content signal across the cluster. | Flag: −10% trend |
Each failure mode pushes content into Zone 1 despite apparent originality effort. Each has a specific, implementable fix.
aiseojournal.net · AI-SEO Design Team · Visual Guide 2026
Data sources: Google Patents (US20200349181A1, 2022) · BrightEdge (2025–2026) · Previsible (2025) · Ahrefs (2025) · Princeton/Georgia Tech KDD (2024) · Yext Q4 (2025) · Seer Interactive (2025) · Wellows · aiseojournal.net internal analysis (2026)
Measuring Information Gain: Metrics, Tools, and Thresholds
Information gain isn’t directly measurable through any current commercial SEO tool. What’s measurable are the proxy metrics that correlate with gain score movement — and they’re specific enough to act on.
| Metric | Tool | Threshold | What Movement Signals |
|---|---|---|---|
| Perplexity citation frequency | Manual tracking or brand monitoring tool | First citation within 60 days of publish = Zone 2+ | Post has at least one original element retrievable by AI systems |
| GSC click-through rate (position-adjusted) | Google Search Console | CTR below 2% at Position 1–5 = differentiation failure | Ranking without clicks = derivative content competing on rank alone |
| AI Overview appearance | GSC → “Search type: All” → filter AI result appearances | First AIO appearance within 45 days = strong gain signal | Content contains a passage-level original claim matching the AIO query |
| Referring domain growth rate | Ahrefs → Backlink profile → New referring domains (30-day) | 0 new domains in 90 days post-publish = Zone 1 risk | Original content earns links; derivative content earns shares at best |
| Indexed page retention | GSC → Coverage → Indexed → 6-month trend | Drop of 10%+ indexed pages across cluster = derivative signal | Google deprioritising crawl of low-gain pages within the cluster |
Table 2: Proxy metrics for information gain score movement with tool paths, thresholds, and interpretive signals. No metric is a direct measure of gain score — these are correlated proxies based on observed post-publication patterns.
The most practically useful entry in that table is the position-adjusted CTR check. A post ranking Position 1–5 with a CTR below 2% is the clearest proxy for derivative content in the dataset: Google surfaces it because it’s topically relevant, but users don’t click because the SERP listing signals nothing differentiated. That gap — visible ranking without click engagement — is what Zone 1 content looks like in GSC before the ranking eventually erodes.
The indexed page retention metric is underused as a gain proxy. When Google starts reducing crawl frequency for pages in a cluster — even pages that are indexed — it’s often an early signal that the cluster’s overall gain contribution is low. You’ll see it in the 6-month indexed trend before it appears in rankings.
Action: Set a GSC date range for the last 90 days. Filter Performance → Pages → sort by Impressions descending. Every page with over 1,000 impressions and under 2% CTR is on your derivative content list. Start with the highest-impression entry. Run claim-level verification on the intro and first two H2s. One post, one first-hand signal addition, one GSC check after 21 days.
Common Failure Modes and How to Fix Them
The Contribution Gradient Model surfaces four failure modes that repeatedly push content into Zone 1 despite genuine originality effort. Each has a named fix.
Failure Mode 1 — Perspective gestures without specificity. A post carries authorial voice — “in my experience,” “what we’ve found,” “practitioners often overlook” — but no named vertical, no named tool, no measurable outcome. Authorial voice signals originality to human readers. The absence of specificity signals zero gain to AI retrieval systems. Fix: convert every perspective gesture into a four-dimension first-hand signal. If the experience can’t be named with vertical + tool + outcome + friction — remove the gesture and make the claim factual instead.
Failure Mode 2 — Original framework without indexed distinctiveness. A post introduces a named framework, assigns it an original label, and defines its components. Every component, though, restates widely indexed principles. The name is original. The content contributes zero gain. Fix: each component of a named framework needs at least one original element — a threshold, a metric, an observed behaviour, or a named relationship not found in the indexed corpus.
Failure Mode 3 — Data without context specificity. A post cites real statistics with named sources. The statistics are already indexed from those same named sources across multiple competing pages. Citing Semrush’s 2025 AI Overview study contributes zero information gain if every competing post already cites the same study. Fix: add an original analytical layer to existing data — what it means specifically for the query context you’re addressing, from direct experience — or find data the corpus hasn’t already indexed from that source.
Failure Mode 4 — Comprehensiveness as a gain strategy. A post aims to cover every subtopic of a broad theme through breadth rather than depth. Comprehensive coverage of already-indexed subtopics contributes zero gain per section. Each additional section adds volume without adding originality. Fix: reduce section count, raise original element density per section. Fewer H2s with one original element each outperforms more H2s with zero original elements — consistently, across the citation data.
The failure mode most guides never name: structural originality mistaken for gain originality. An unusual article format, an unconventional heading structure, a distinctive visual approach — these signal authorial creativity. They contribute zero information gain. The retrieval system doesn’t evaluate format. It evaluates whether your content holds something the corpus doesn’t.
Action: Take your last published post. Read every H2 body paragraph. For each paragraph, ask: does this contain a named vertical, a named tool, a measurable outcome, or a named entity relationship not in the top 5 indexed results for this keyword? If the answer is no for every paragraph in an H2 — that entire H2 is Zone 1. It doesn’t need rewriting. It needs one original element added. One sentence. Four dimensions.
The Information Gain SEO Cluster: What Each Post Covers
Six cluster posts map to this pillar — covering distinct implementation aspects of information gain SEO. None are live yet; this section previews the coverage as posts publish.
How Google Measures Information Gain: Patents, Signals, and Quality Scoring — Deep-dives into the US20200349181A1 patent language, how the scoring mechanism is described technically, how it connects to the Helpful Content System’s quality signals, and what practitioners can infer about threshold behaviour from observed post-publication patterns.
Original Research for SEO: How to Create Data That Earns Citations and Links — A production guide for creating survey data, proprietary analytics findings, and structured experiments that reliably produce Zone 3 information gain elements. Covers sampling design, stat freshness requirements, and how to frame original data for maximum citation eligibility in both Google and AI search systems.
Content Differentiation Audit: How to Find and Fix Zero-Gain Sections in Your Posts — Step-by-step walkthrough of the claim-level verification process described in this pillar, with a downloadable audit template, GSC integration for prioritisation, and a decision tree for deciding whether a section needs a first-hand addition, a data addition, or complete removal.
Derivative Content Penalty: Why Summarising Competitors Hurts Your Rankings — Covers the observed ranking suppression pattern in derivative content clusters, how the HCS and information gain scoring interact to create the penalty, and a recovery sequence for content portfolios where derivative synthesis posts are dragging down overall cluster authority.
Information Gain for AI Citations: How Perplexity and ChatGPT Select Unique Sources — Platform-specific breakdown of how Perplexity, ChatGPT web browsing, Google AI Overviews, and Claude.ai handle citation selection — with specific differences in how they weight source recency, entity specificity, and content gain score in their retrieval and citation logic.
Proprietary Examples and First-Hand Signals: The Easiest Way to Raise Information Gain — Production-level guide to generating first-hand signals systematically from client work, analytics data, and professional experience — with naming conventions, specificity checklists, and a signal library structure for teams producing content at scale.
Frequently Asked Questions
What is information gain in SEO and how does Google measure it? Information gain in SEO is Google’s signal for measuring how much new knowledge a piece of content adds to the indexed corpus on a specific query. Google’s patent US20200349181A1 describes a system scoring documents based on additional information beyond what’s already in the candidate set. It operates at passage level — meaning individual sections of your post are scored independently. A post with eight derivative sections and one high-gain passage still earns citation eligibility for that passage.
Does writing quality affect information gain scores? No — not directly. Writing style, structural quality, and length have no measurable correlation with information gain score. What raises the score is the presence of original content elements: named data points, first-hand practitioner observations with vertical and tool specificity, novel entity relationships not already indexed, and named frameworks with original component definitions.
Can a short post score high on information gain? Yes. Length doesn’t determine information gain — contribution does. A 1,500-word post containing one original data point, one four-dimension first-hand observation, and one named entity relationship not in the corpus can outscore a 5,000-word synthesis on the same topic. Google’s patent system evaluates contribution at passage level, independent of surrounding volume.
What is the difference between information gain and E-E-A-T? E-E-A-T — Experience, Expertise, Authoritativeness, Trustworthiness — is Google’s quality evaluation framework for the overall credibility of a content source. Information gain is a per-document, per-query signal measuring originality of contribution. A post can carry strong E-E-A-T signals and near-zero information gain if the content doesn’t add anything the corpus doesn’t already hold. E-E-A-T signals who the source is; information gain signals what new knowledge the source contributes.
How does information gain affect AI Overview appearances? Google AI Overviews select citation candidates at passage level — the same mechanism the information gain patent describes. Posts with Zone 2 or Zone 3 content on the Contribution Gradient Model have higher AI Overview appearance rates than Zone 1 content. Track appearances via GSC → filter “Search type: All” → look for AI result appearances. First appearance within 45 days of publishing = Zone 2 minimum confirmed.
Is it possible to audit existing content for information gain without tools? Yes. Run claim-level verification manually: for every core claim in a section, search the claim as a Perplexity query. Count how many of the top 3 cited sources already make the same claim with the same data. If 3 or more do — that claim contributes zero gain. If over 60% of claims in an H2 return 3+ existing sources — that H2 is Zone 1. Flag it for a first-hand signal addition before the next update cycle.
How do AI systems like Perplexity select which posts to cite? Perplexity and similar retrieval systems select citation candidates at retrieval stage based on whether the candidate document holds information not available from other candidates for the same query. Posts with Zone 3 content — multiple original data points, named entity relationships not indexed elsewhere, first-hand observations with four-dimension specificity — are selected at highest frequency. Zone 1 content is rarely surfaced as a candidate regardless of domain authority or backlink profile.
How Information Gain Changes the Work
The Contribution Gradient Model doesn’t make content production easier. It changes the question you’re answering before you start writing.
The old question: have I covered everything the reader needs to know? That’s a comprehensiveness question. It produces comprehensive, derivative posts — and Zone 1 citation frequency.
The new question: what does this post contain that the indexed corpus doesn’t? That’s a contribution question. It produces shorter, more specific posts with higher citation frequency and more durable ranking positions.
Worth naming plainly: you’ll spend more time on research and less time on writing. You’ll publish fewer posts per month and earn more citations per post. The competition shifts from volume to originality density — the number of original elements per 1,000 words rather than the number of words per post.
The model gives you a scoring framework for that shift: audit existing content against the three zones, find posts where a single first-hand signal addition moves them from Zone 1 to Zone 2, prioritise those updates over new post production, and track proxy metric movement in GSC over the following 30–45 days. Most content teams have Zone 1 inventories measured in the hundreds of posts. They don’t need more content. They need one original element per post.
Explore the AI Content & EEAT Guidelines category for the cluster posts as they go live — starting with the patent deep-dive and the content differentiation audit.
Your specific next action: open GSC → Performance → Pages → sort by Impressions → filter to the last 90 days. Find the page ranked in Position 1–10 with the highest impressions and the lowest CTR. That’s your highest-priority Zone 1 post. Open it. Find the H2 with the most generic claim — no named vertical, no tool, no outcome. Add one first-hand observation this week: vertical + tool + outcome + what didn’t work as expected. Publish the update. Check GSC in 21 days. If CTR moves — you’ve confirmed your first information gain intervention, and that confirmation is worth more than any amount of theory.
References
Google. “Contextual Estimation of Link Information Gain.” Patent US20200349181A1. Filed October 2018, published November 2020, granted June 2022. https://patents.google.com/patent/US20200349181A1/en Supports: The definition, mechanism, and passage-level scoring description of information gain as a documented Google technical system.
Google Search Central. Creating Helpful, Reliable, People-First Content.” Updated December 2025. https://developers.google.com/search/docs/fundamentals/creating-helpful-content Supports: Google’s explicit guidance that content must provide original information, reporting, research, or analysis — and must add substantial value beyond synthesising existing sources.
Search Engine Land. “Information Gain in SEO: What It Is and Why It Matters.” 2023. https://searchengineland.com/what-is-information-gain-seo-why-it-matters-429763 Supports: The mechanism by which information gain scoring functions as a promotion or demotion signal based on a document’s uniqueness relative to the indexed corpus — and its connection to how AI retrieval systems evaluate citation candidates.
Search Engine Journal. “Google’s Information Gain Patent for Ranking Web Pages.” February 2025. https://www.searchenginejournal.com/googles-information-gain-patent-for-ranking-web-pages/524464/ Supports: The per-query, per-candidate-set scoring mechanism and its specific relevance to AI Overviews and agentic search citation selection.
Semrush. What Is Information Gain in SEO and Does Google Measure It?” February 2025. https://www.semrush.com/blog/information-gain/ Supports: Industry interpretation of the information gain patent’s practical implications for content strategy, including the connection to Google’s Helpful Content Update reward patterns.
Clearscope. Information Gain in SEO: The Guide to Rethinking Current Strategies.” 2024. https://www.clearscope.io/blog/information-gain-seo Supports: The competitive positioning problem derivative content faces in an AI Overview environment — AI systems surface consensus information, making Zone 1 content directly competitive with AI answers rather than complementary to them.
Google Search Central Blog. “Google Search’s Guidance About AI-Generated Content.” Danny Sullivan and Chris Nelson, Google Search Quality Team. 2023. https://developers.google.com/search/blog/2023/02/google-search-and-ai-content Supports: Google’s confirmed position that ranking systems reward original, high-quality content demonstrating E-E-A-T — the framework within which information gain operates as a complementary contribution signal.
aiseojournal.net. Perplexity Citation Analysis — 90 Queries, SEO and AI Search Vertical.” Internal analysis, February–April 2026. https://aiseojournal.net/ Supports: The 5.1x citation frequency finding — posts with at least one original data point or named first-hand signal are cited 5.1x more frequently than length-matched posts without original content elements. Writing style and structure: non-significant correlation.











